1. Introduction
기존의 semantic vector space model은 각각의 단어를 실수로 이루어진 벡터로 임베딩 한다. 대부분 단어 벡터의 학습 방법은 단어 벡터 간의 거리나 각도를 기반으로 벡터의 품질을 평가해왔다. 하지만 Word2Vec이 등장하면서, 다양한 차원의 차이로 단어를 표현하는 방법도 생겼다. 예를 들면 'King - queen = man - woman'과 같은 벡터 방정식으로 단어의 의미를 표현할 수 있게 되었다.
기존의 대표적인 모델은 아래와 같다.
1.1 Global Matrix Factorization (ex. LSA)
LSA는 통계 기반의 의미 분석 방법이다. 단어-문서의 행렬을 만들고, 특이값 분해(SVD)를 통해 차원을 축소하여 단어 간의 의미 관계를 파악한다. 쉽게 말해, 비슷한 문맥에 등장하는 단어들은 의미가 비슷하다는 Distributional Hypothesis에 기반한다. corpus 전체의 공동 등장 빈도를 반영하는 것이다.
전체 corpus의 정보를 활용하기 때문에 의미 구조 전체를 잘 포착하며, 수학적으로 직관적인 행렬 분해 방식에 기반한다는 장점이 있지만, 희소한 단어에 약하고 계산 비용이 크다는 단점이 있다. 무엇보다도 단어의 빈도에 기반하기 때문에 단어 간 유사도 측정에서는 성능이 좋지 않다.
1.2 Local Context Window (ex. Skip-gram)
Skip-gram은 local context 기반 예측 모델이다. 중심 단어를 입력으로 주고, 주변 단어를 예측하는 확률 기반의 신경망 모델이다. Skip-gram은 단어의 의미를 주변 단어로부터 예측할 수 있다는 것이 핵심 아이디어다. 통계 기반의 LSA와는 달리 단어 간 벡터 연산이 가능해 단어를 유추하고, 의미의 유사성을 측정하는 데에서 뛰어난 성능을 보인다.
그러나 전체 corpus가 아니라 local context만을 고려하기 때문에 전체적인 통계 정보를 충분히 반영하기 어렵다는 한계점을 지닌다.
1.3 Goals
이렇듯 기존의 두 방법은 모두 중대한 한계점을 가진다. LSA는 통계 정보를 효율적으로 반영하지만 단어 의미의 유사성을 정밀하게 측정하기 어렵고, Skip-gram은 의미간 유사성은 잘 예측하지만 corpus 전체의 통계 정보를 충분히 활용하지 못한다.
본 논문에서는 이 두 모델의 단점을 보완해 결합하고자 하였다. 의미의 선형 방향(linear directions of meaning)을 잘 표현하기 위한 모델의 특성을 분석하고, 이를 위해 global log-bilinear regression 모델을 제안한다. 구체적으로는, 전역 단어-단어 동시 등장 빈도 (global word-word co-occurrence counts)를 활용한 가중 최소제곱 회귀(weighted least sqaures) 방식을 도입하며, 의미 구조가 잘 반영된 벡터 공간을 구성한다. 즉, 전체 corpus의 통계 정보를 반영하면서 높은 성능의 유사도 측정을 가능하게 하는 모델을 제시하는 것이 목표이다.
2. The GloVe Model
GloVe는 global corpus를 이용해 통계적 정보를 이용하면서도 단어의 의미론적 정보도 capture 한다.
2.1 Notation
corpus에서의 단어 출현 통계는 단어 표현(word representation)을 학습하는 모든 비지도 학습의 핵심 정보 원천이다. 어떻게 이러한 통계로부터 의미가 생성되는가? 그리고 그 결과로 생성된 단어 벡터는 어떻게 의미를 표현하는가?
이것을 설명하기 위해 먼저 몇 가지 기호를 정의해야 한다.
| 수식 | 의미 |
| co-occurrence matrix (X) 단어-단어 동시 등장 빈도 행렬 | |
| Xi=∑kXik | 단어 i의 문맥에 등장한 모든 단어들의 총합 |
| 단어 i의 문맥에 단어 j가 등장할 확률 |
GloVe는 단어가 동시에 등장할 확률로 단어의 의미를 나타낸다. 예시를 살펴보자.
위의 정의에 따라 단어 i는 ice, j는 steam, 그리고 탐색 단어 k(various probe words)를 통해 의미를 파악할 수 있다. 아래의 예시에선는 ice와 steam이라는 단어의 관계를 파악하기 위해 주변 단어 k를 이용하고자 한다. 아래 표에서 3번째 행을 주목해보자. 3번째 행에서는 확률의 비율을 나타내고 있다.
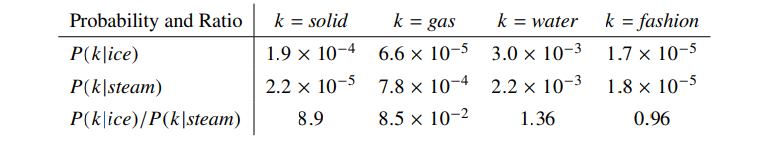
확률의 비율은 무엇을 의미할까?

- : 단어 i가 중심 단어일 때, k라는 단어가 그 문맥(context)에 등장할 확률
- : 단어 j가 중심일 때, k가 문맥에 등장할 확률
즉 확률의 비율은 탐색 단어 k가 i와 더 관련이 깊은지, j와 더 관련이 깊은지를 보여준다.
예시 상황에 대입해보자. k=solid 일 때,
- : "ice" 주변에 "solid"가 등장할 확률
- : "steam" 주변에 "solid"가 등장할 확률
Table1에서 P(solid∣ice) / P(solid∣steam) = 8.9로, solid는 ice와 더 관련이 깊다는 것을 수치적으로 보여준다.
이 두 확률의 비율이 1보다 크다면 k는 i에 더 관련이 있다는 것이고, 비율이 1보다 작다면 k는 j에 더 관련이 있다는 것이다. 확률의 비율이 1에 가깝다면, k는 i와 j 모두와 비슷하게 관련 있거나, 혹은 무관하다는 것을 의미한다.
기존의 모델에서는 단순히 확률 혹은 빈도를 보고 의미를 추론했지만, GloVe에서는 이렇듯 확률의 '비교'에 초점을 맞춰서 의미의 차이를 더욱 정밀하게 반영한다. '이 단어가 얼마나 자주 나오느냐' 보다, '이 단어가 어떤 단어들과 상대적으로 더 자주 나오느냐'가 핵심인 것이다.
우리는 이러한 동시 등장 확률 비율을 통해 관련 있는 단어를 더 쉽게 구별해낼 수 있게 되었다. 이제 이것을 general한 식으로 가정해보자.
2.2 Model
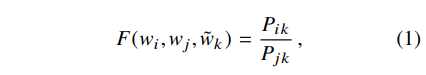
우리가 구하고자 하는 P(i|k) / P(j|k)는 벡터 wi, wj, wk 에 의존한다. w는 단어 벡터이고 w~은 주변 단어 (탐색 단어) 벡터이다. 우리는 이 세 벡터를 통해 위와 같은 임의의 함수 F로 일반적인 목적 함수를 설정할 수 있다.
우리는 함수 F가 비율 P(i|k) / P(j|k) 에 담긴 정보를 단어 벡터 공간 안에 잘 인코딩하길 원한다. 벡터 공간은 선형 구조(linear structure)이므로, 이를 표현하는 가장 자연스러운 방법은 벡터의 차이(difference)를 이용하는 것이다.
쉽게 설명해보자면 이렇다.
벡터를 방향과 크기를 가진 화살표라고 생각했을 때, 우리는 벡터 공간 안에서 두 화살표를 더하거나 스칼라를 곱해 새로운 벡터를 만들 수 있다. 이러한 연산이 가능하다는 것은 선형 구조를 가지고 있다는 것을 의미한다.
그렇다면 벡터의 차이를 이용한다는 것은 어떤 의미일까? 선형 구조를 가지는 벡터 공간 안에서, 우리는 단어의 의미를 벡터 차이를 통해서 나타낼 수 있다.
예를 들면, king - queen = man - woman 처럼, king과 queen의 단어 의미 차이가 남성과 여성임을 벡터 간 차이로 나타낼 수 있는 것이다.
정리하자면 벡터 공간은 선형적이기 때문에, 두 단어 (벡터) 간의 차이가 그들의 의미적 관계를 잘 나타낼 수 있다는 것이다. 벡터 차이를 이용해 단어 간의 의미적 관계를 수학적으로 표현할 수 있고, GloVe에서는 확률 비율을 벡터 차이로 표현해 단어 간의 의미 차이를 표현하고자 한다.
따라서 이러한 특성에 기반해 Eqn.(1)을 변형해 아래와 같이 나타낸다.

위 수식처럼 두 타겟 단어 벡터의 차이에 의존하는 함수 F를 정의했다. 이렇게 하면 동시 등장 확률의 크기 관계 비율을 벡터 공간에 인코딩 할 수 있다.
위 수식에서 좌변의 F 함수는 벡터 값, 우변은 상수로 정의된다. 즉, 지금 식에서 함수 F는 벡터 두 개를 입력으로 받고, 스칼라 하나를 반환하고 있다. 수식을 더 다루기 쉽게 하려면 벡터를 숫자로 변환하는 과정이 필요하다.

같은 차원의 벡터를 곱하면 하나의 숫자를 만들어줄 수 있으므로, GloVe에서는 내적을 통해 위와 같이 함수를 완성했다.
여기서 한 가지 궁금증이 생긴다. 신경망을 사용해 복잡한 함수로 만들수도 있었을텐데 GloVe는 왜 내적이라는 방법을 택했을까? 두 가지 이유가 있다.
첫째, 내적은 벡터의 선형적인 관계를 잘 유지해주는 방법이다. 신경망을 활용한다면 우리가 capture 하고자 하는 단어 사이의 선형 관계가 난독화되어 파악하기 어려워질 수 있다.
둘째, 내적값이 크다는 것은 두 벡터가 방향도 비슷하고 크기도 크다는 것을 의미한다. 즉, 내적값을 통해 이 두 벡터가 서로 관련이 있다는 것을 수치적으로 나타내기 좋다.
하지만 여기서 문제가 하나 더 발생한다. GloVe는 단어 벡터와 문맥 단어 벡터를 따로 가지고 있다.
| 단어 벡터 | w |
| 문맥 벡터 | w~ |
그런데 사실 단어와 문맥 단어의 역할은 서로 바꿔도 큰 의미 차이가 없을 수 있다. 문장으로 예시를 들어보자.
| The king sat on his throne.
위와 같은 문장에서 king이 중심 단어이고 throne이 문맥일 수도 있고, throne이 중심 단어이고 king이 문맥 단어일 수도 있다. 하지만 (i,k)의 관계에서 (king, throne)과 (throne, king)은 같은 의미 관계를 가진다. i와 j가 서로 교환 가능한 관계라는 의미이다.
이렇게 GloVe에서는 단어(i)와 문맥 단어(k)의 기준이 임의적이다. 두 요소의 순서나 위치를 바꿔도 같은 결과가 나오려면(교환 가능하려면), 준동성(homomorphism)을 만족해야 한다. 그러나 앞서 본 수식 Eqn(3)에서는 두 요소의 역할을 바꾸면 결과가 달라진다. 따라서, 수식 구조를 바꾸어서 좌우 역할을 바꿔도 같은 결과가 나오도록 해야한다.
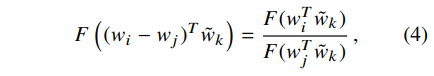
뺄셈에 대한 동형사상(homomorphism)은 F(a-b) = F(a) / F(b)와 같으므로, 수식을 위와 같이 정리할 수 있다. Eqn(3)과 Eqn(4)를 이용하면 아래와 같은 Eqn(5)를 도출할 수 있다.

F(a-b) = F(a) / F(b)를 만족하는 함수는 지수함수 이므로, F(x) = exp(x)로 표현할 수 있다. 그리고 지수함수의 역함수는 로그함수이므로, 양변에 로그를 취하면 아래와 같은 수식이 완성된다.

Eqn (6) 을 살펴보면 log(Xi)를 제외한 나머지 항들은 i와 k가 값이 바뀌어도 값이 똑같다. 즉, log(Xi)만 없으면 교환 가능한 관계를 충족할 수 있기 때문에 log(Xi)를 wi에 대한 편향 bi와 wk~에 대한 편향 bk~로 대체한다. 그러면 아래와 같은 수식이 완성된다.
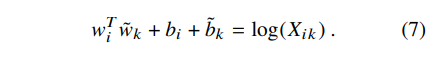
왜 이런 가중치가 필요할까? the, and, of 와 같이 너무 자주 등장하는 단어는 값이 너무 커지고, 또 너무 드물게 등장하는 단어는 노이즈일 수 있기 때문에 학습이 제대로 이루어지지 않을 수 있다. 이때 가중치를 부여함으로써 단어의 빈도에 따라 더 중요하거나 덜 중요하게 학습하도록 할 수 있다.
하지만 또다른 문제가 발생한다. Xik = 0 일 떄, log 값이 발산하게 된다. 따라서 여기에 1을 더해주어 동시 등장 행렬 X의 sparsity를 유지하면서 문제를 해결한다.

이 과정을 거쳐 최종적으로 완성된 손실함수는 위와 같다. GloVe 모델이 Eqn (7) 에서의 좌변과 우변이 같아지기를 원하기 때문에 최소 제곱법을 이용해 이를 최소화 하고자 하는 손실 함수로 이용한다. 그리고 가중치 항 f(Xij)를 추가하는데, 등장 횟수에 따라 가중치를 곱해 흔한 단어는 너무 많이 반영되지 않게 조절한다.
가중치의 수식은 아래와 같다.

수식을 자세히 살펴보면 단어 i와 j의 공동 등장 횟수에 따라 손실 함수에 얼마만큼 가중치를 줄지 결정하는 함수이다. 이 가중치 함수는 아래의 조건을 만족한다.
- f(0) = 0 이다. Xij = 0일 때 log가 발산하는 것을 방지한다.
- rare co-occurrence에 대해 높은 가중치를 주지 못하도록 non-decreasing 이어야 한다.
- too frequent co-occurence에 대해 너무 높은 가중치를 주지 않기 위해 x_max를 정해 가중치가 계속해서 증가하지 않게 해야한다.
정리하면, 희귀한 단어쌍은 노이즈일 가능성이 있기에 학습에 과도하게 반영하지 않도록, 너무 자주 나오는 단어쌍은 의미 없는 단어일 수 있기에 일정 이상 크게 반영되지 않도록 설계되어 있다. 그래프로 보면 아래와 같다.

3. Relationship to Other Models
논문에서 제안한 모델과 기존의 모델들이 어떤 관련이 있는지 살펴보자. 단어 벡터를 학습하는 모든 비지도 학습 기법은 occurence statistics에 기반하기 때문에, 분명히 모델들 간의 공통점이 존재한다.
3.1 Relationship to Skip-gram & ivLBL
Skip-gram 모델은 다음과 같은 확률 분포를 정의함으로써 시작한다. 단어 i에 대한 문맥에서 단어 j가 나타날 확률을 Qij로 모델링하는 것이다. 여기서 Qij는 소프트맥스 함수라고 가정한다.

이러한 모델들은 윈도우를 기반으로 학습하는데, 실제 문맥에서 자주 나왔던 단어쌍일수록 Q값을 높이도록 학습한다. 수식으로 나타내면 아래와 같다.

수식을 자세히 살펴보면, Skip-gram 모델은 학습할 때 문장 전체를 스캔하면서 중심 단어 i와 그 주변 단어들 j에 대해 각각 log Qij 값을 더해서 학습한다. 그런데 여기서 Qij는 소프트맥수 함수이므로, 계산이 너무 느려지는 문제가 발생한다.
이러한 문제를 해결하기 위해 Skip-gram은 negative sampling 혹은 hierarchical softmax를 활용해 Qij를 근사로 계산한다. 쉽게 말해, 계산이 오래 걸리니까 효율적으로 학습하기 위해 근사를 도입한다는 것이다.

Eqn (11)의 수식을 전체 코퍼스 기반의 전역 수식으로 바구어 나타내면 Eqn (12)와 같다. 단어 i와 j가 corpus에서 같은 문맥에 등장한 횟수 Xij를 미리 세어놓고, 등장 횟수 Xij 만큼 로그 확률을 손실로 더해준다. 쉽게 말해, 전체 문서를 한 번 훑어서 등장 횟수를 먼저 세어놓는 방식이다.

Eqn (12)가 전체 손실 함수 J를 나타내고 있다면, 이것을 중심 단어 i별로 정리해서 크로스 엔트로피를 계산한 식이 위와 같다. 쉽게 말해, 중심 단어 i에 대해 실제 문맥 분포 Pi와 모델이 예측한 분포 Qi가 얼마나 다른지를 크로스 엔트로피로 측정하고, 그 loss 값을 Xi 만큼 가중합 해서 전체 loss를 계산한다.
여기서 문제가 두 가지 발생한다.
먼저 크로스 엔트로피는 확률 분포의 거리를 측정하는 여러가지 방법 중 하나인데, 확률 분포의 long tail이 일어날 것 같지 않은 사건에 과도하게 가중치를 할당하는 문제가 발생할 수 있다. 그러니까, 등장 빈도가 낮은 희귀 단어에 과도한 가중치를 부여할 수도 있다는 의미이다.
둘째로 정규화가 필요하다는 문제가 있다. Qij를 계산하려면 softmax 분모를 게산해야 하기 때문에 매번 전체 단어 집합을 다 훑어야 한다. 그러면 계산 비효율이 발생할 수 밖에 없다.
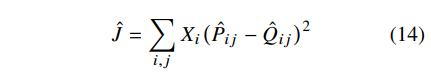
이러한 문제를 해결하기 위해 GloVe는 위와 같은 방식을 제안한다. 정규화 과정이 제거된 최소 제곱(least squares ovjective)을 사용하는 것이다.
GloVe는 정규화를 무시함으로써 굳이 확률로 만들지 말고, 등장 횟수 자체를 이용해 더 간단하고 빠르게 학습을 진행하고자 하였다. 정확한 확률이 아니라, 단어 벡터의 차이와 유사도 관계를 잘 반영하는 벡터 공간을 만드는 것이 목표이기 때문이다. '얼마나 자주 같이 등장했는지'를 로그 등장 횟수로 표현해도 충분히 좋은 벡터가 나올 수 있다.
Eqn (14)를 자세히 살펴보자.
- : 실제 공동 등장 수
- : softmax 정규화 제거한 예측값
이다. 즉, 확률 대신 등장 횟수 자체를 비교하고, 정규화를 하지 않는다. 하지만 Xij의 값이 너무 커져 최적화가 어려워질 수도 있기 때문에 등장 횟수에 로그를 씌워 스케일을 안정화한다.

마지막으로 너무 자주 등장하는 단어쌍은 과도하게 손실에 영향을 줄 수 있고, 너무 드물게 나오는 단어쌍은 노이즈일 수 있기 때문에 빈도에 따라 학습 중요도를 조절할 수 있도록 가중치 함수를 추가해준다. 그렇게 최종적으로 나온 수식은 아래와 같다.
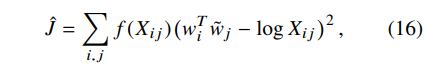
그리고 이것은 Eqn (8) 의 수식과 동일하다. 이러한 과정을 거쳐 GloVe는 기존 방식의 단점들을 하나씩 해결해 손실 함수를 완성했다.
3.2 Complexity of the model
모델의 계산 복잡성을 살펴보자.
GloVe 모델이 학습할 때 사용하는 손실 함수 Eqn (8)을 보면 알 수 있듯이, 동시 등장 행렬 X에서 nonzero인 원소의 개수에 따라 그 복잡도가 계산된다. Xij > 0 일 때만, 즉 실제로 두 단어가 함께 등장했을 때만 계산하기 때문이다. (GloVe는 동시 등장 행렬에서 0인 항목(= 동시에 등장하지 않은 단어쌍)에 대해서는 아예 손실 함수에 포함시키지 않고 계산하지 않는다.
즉, 모델이 실제로 학습에서 처리하는 데이터는 전체 조합 중 등장한 단어쌍만 해당한다. 이때, 0이 아닌 항의 개수는 행렬 전체 항목 수보다는 항상 작을 수 밖에 없다.
언뜻 보면 전통적인 윈도우 기반 shallow 모델들보다 훨씬 나아 보일 수 있다. 윈도우 기반의 모델들은 corpus의 크기 |C|에 따라 복잡도가 선형적으로 증가하기 때문이다. 하지만 현실에서 어휘 수는 수십만 개에 이르기 때문에 행렬 전체 항목 수, 즉 Vocabulary의 크기인

멱함수(power-law)란 어떤 값이 순위가 낮을수록 압도적으로 많이 등장하고, 순위가 높을수록 급격히 줄어드는 분포를 말한다. 예를 들면 다음과 같다.
| rank 1 | 1만 번 등장 |
| rank 2 | 5천 번 등장 |
| rank 3 | 3천 3백 번 등장 |
이런 식으로 급격히 줄어드는 패턴을 멱함수(power-law)라고 한다.
GloVe에서는 동시 등장 행렬 Xij의 값들이 해당 단어쌍의 rank에 따라 멱함수의 분포를 따른다고 가정한다. 이 가정에 따라 Eqn (17) 에서 k는 전체 스케일을 조정하는 상수, α 는 얼마나 빠르게 줄어드는지 결정하는 지수이다.
이 분포를 이용하면, 전체 단어쌍 중에서 실제로 등장한 단어쌍이 얼마나 될지를 추정할 수 있다. Xij가 클수록, 즉 동시 등장 빈도 수가 높을수록 순위 r_ij는 낮아지는 반비례 관계가 성립한다.
다시 정리해보자.
1) GloVe는 동시 등장 행렬 Xij에서 0이 아닌 값, 실제로 등장한 단어쌍에 대해서만 학습한다.
2) 따라서 GloVe의 계산 복잡도는 실제로 등장한 단어쌍의 개수 (=동시 등장 행렬에서 0이 아닌 값)에 따른다.
3) 그렇다면 실제로 등장한 단어쌍은 몇 개일까? 이것을 수학적으로 추정하기 위해 멱함수를 활용한다.
4) 멱함수 분포를 따르는 r_ij와 Xij 사이에는 반비례 관계가 성립한다. 즉, 동시 등장 빈도 수가 높을수록 순위는 작다.
GloVe는 복잡도 추정을 쉽게 하기 위해, 단어쌍 하나하나의 등장 횟수를 다루는 대신 등장 순위를 기반으로 멱함수 모델을 도입해 단어쌍이 얼마나 자주 등장하는지 전체적인 패턴을 수학적으로 표현하고자 한 것이다.

최종적으로 GloVe에서 동시에 등장한 단어쌍의 총합은 문서 전체의 corpus 크기와 비례한다. 수식을 뜯어보면 r의 upper limit이 |X|로 설정되어 있다. |X|는 nonzero 원소의 총 개수니까, Xij = 0인 경우는 rank를 아예 고려하지 않게 된다. 만약 |X|가 5라면? 마지막 항의 rank는 5위가 되고, r이 커짐에 따라 동시 등장 횟수 Xij는 작아진다. 이렇게 하면 복잡도 추정을 쉽게 할 수 있다!
이런 과정을 거쳐 최종적으로 본 논문에서 제시하는 GloVe의 계산 복잡도는 아래의 수식과 같다.
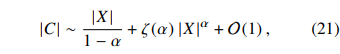

4. Experiments
4.1 Evaluation Methods
본 논문에서는 다음의 세 가지 방식으로 GloVe 모델의 성능을 실험했다.
- Word analogy task : 단어 유추
- Word similarity task : 단어 유사도
- CoNLL-2003 Named Entity Recognitioon (NER) benchmark : 개체명 인식
(1) Word analogy task 단어 유추
단어 유추는 a와 b가 같다. 그러면 c는? 형태의 문제로 구성되어 있다. 즉, b - a + c 벡터에 가장 가까운 단어 벡터를 찾는 방식이다.
| 의미 유추 | Athens : Greece = Berlin : ? |
| 문법 유추 | dance : dancing = fly : ? |
(2) Word similarity 단어 유사도
아래의 데이터셋을 사용해 단어의 유사도도 평가하였다.
- WordSim - 353
- MC (Miller & Charles)
- RG (Rubenstein & Gooodenough)
- SCWS
- RW (Luong et al.)
(3) Named Entity Recognition (NER) 개체명 인식
사람, 장소, 조직, 기타 등 4가지 객체 타입에 대해 표기된 문서 집합 CoNLL-2003 benchmark를 활용하였다. 훈련 데이터에 대해 학습시킨 후, 아래의 3가지 데이터에 대해 테스트 하였다.
- CoNLL-03 test set
- ACE Phase 2, ACE-2003
- MUC7 테스트셋
4.2 Corpora and Training Details
GloVe는 크기가 서로 다른 5개의 corpus로 모델을 학습했다.
- 2010 Wikipedia dump: approximately 1 billion tokens
- 2014 Wikipedia dump: approximately 1.6 billion tokens
- Gigaword 5: approximately 4.3 billion tokens
- Gigaword 5 + Wikipedia 2014 combined: total of 6 billion tokens
- Common Crawl web data: approximately 42 billion tokens
모든 corpus는 stanford tokenizer를 이용해 토큰화하고 소문자로 변환 후 가장 자주 등장한 상위 40만 개의 단어로 vocab을 만들었다. 그리고 해당 vocab을 바탕으로 동시 등장 행렬 Xij를 구성했다.
모든 경우에 대해 감소하는 가중치 함수를 적용하였다. 두 단어가 d만큼 떨어져있으면, 해당 단어쌍은 등장 횟수에 1/d 만큼 기여하게 된다. 이는 멀리 떨어진 단어쌍일수록 서로 관련된 정보가 적을 것이라는 가정을 반영한 것이다.
모든 실험에서 x의 max값은 100, α 값은 3/4로 통일하였으며 학습 시 X의 0이 아닌 항목을 stochastic하게 샘플링해서 사용, 초기 학습률을 0.05로 두었다.
모델은 중심 단어 벡터 W와 문맥 단어 벡터 W~, 두 종류의 벡터를 학습했다. 만약 X가 symmetric 이라면 W와 W~는 초기값만 다르고 거의 동일한 성능을 보인다. 그래서 최종 단어 벡터를 W + W~로 정의하였다. 두 벡터를 더해서 하나의 벡터로 사용한 것이다.
4.3 Results
결과는 아래와 같다. GloVe 모델은 다른 베이스라인 모델들 보다 훨씬 더 좋은 성능을 보였다. 더 작은 벡터 차원과 더 작은 말뭉치를 사용했음에도 성능이 뛰어났다.
(1) word analogy task

성능 평가 결과는 위와 같다. 여러 Dim과 training Size에서 좋은 성능을 보였음을 알 수 있다. Word2Vec의 skip-gram 모델(SG)보다 성능이 높았다. 특히 의미 유추 문제에서 차이가 크다. 이는 GloVe가 단어 벡터 간의 구조적인 관계를 더 잘 학습하고 반영할 수 있다는 것을 의미한다.
GloVe는 420억 토큰 규모의 대규모 corpus에서도 쉽게 학습될 수 있음을 보였고, 이로 인해 성능이 크게 향상된 것을 확인할 수 있었다. 하지만, 다른 모델의 경우 corpus의 크기를 키운다고 해서 항상 성능이 좋아지는 것은 아니었다. SVD-L을 보면 corpus가 커질수록 오히려 성능이 떨어지기도 한다.
이를 통해 본 논문에서 제안하듯이 단어 등장 빈도에 가중치를 잘 조절하는 방식이 필요하다는 것을 알 수 있다.
(2) word similarity task
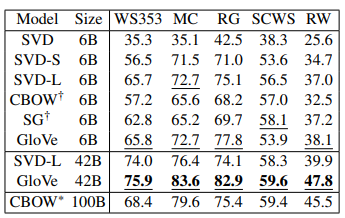
벡터의 각 차원을 정규화한 후 cosine similarity로 단어 간 유사도를 계산했다. 이 값과 사람이 판단한 유사도 점수 간의 spearman rank correlation을 계산해 성능을 나타냈다. GloVe는 훨씬 더 작은 corpus를 사용했음에도 CBOW 보다 더 좋은 성능을 보였다.
(3) Named Entity Recognition (NER)

50차원의 벡터로 NER task에 대한 F1-score를 측정하였다. Discrete은 word vector가 없는 baseline을 나타낸다. GloVe 모델은 CoNLL test set을 제외한 모든 evaluation metrics에 대해 뛰어난 성능을 보였다.
결론적으로, GloVe는 word analogy, word similarity, NER의 평가에서 전반적으로 기존의 Word2Vec, SVD, 기타 신경망 기반 모델보다 전반적으로 더 좋은 성능을 보였다. 특히, 작은 차원과 작은 corpus로도 높은 성능을 낼 수 있다는 강점을 가지고 있다.
5. Model Analysis
5.1 Vector Length and Context Size
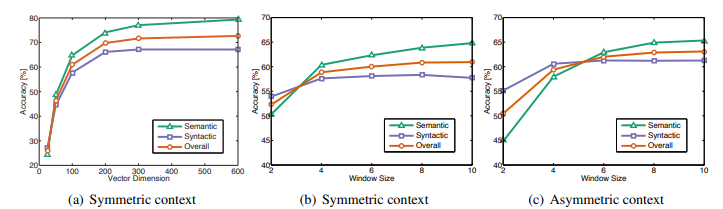
Figure 2는 벡터의 차원 수와 context window의 크기를 변화시킨 실험 결과를 보여준다.
| symmetric context | 중심 단어 기준 왼쪽/오른쪽 문맥을 모두 보는 것 |
| asymmetric context | 왼쪽 단어만 보는 것 |
(a)는 window size를 10으로 고정, (b)와 (c)는 vector dimension을 100으로 고정한 결과이다.
(a)를 보면, 약 200차원 이후부터는 성능 향상이 줄어든다는 것을 알 수 있다. 즉, 너무 큰 차원 수는 비효율적일 수 있다. (b), (c)를 보면, asymmetric은 문법 유추 문제에서 성능이 더 좋고, symmetric은 의미 유추 문제에서 성능이 더 좋다. 조금 더 자세히 살펴보면, 문법 유추 문제(syntatic)의 경우 window size가 작고 asymmetric 할 때 높은 성능을, 의미 유추 문제 (semantic)의 경우 window size가 크고 symmetric 할 때 높은 성능을 보였다.
이는 문법 유추 문제의 경우 단어 순서나 가까운 주변 단어에 크게 의존하기 때문에 asymmetric 할 때 성능이 더 좋고, 의미 정보는 좀 더 넓은 범위에서 얻어지는 경우가 많기 때문에 symmetric하고 window size가 더 클 때 성능이 좋음을 알 수 있다.
5.2 Corpus Size
아래의 Figure 3은 서로 다른 corpus에서 300차원 vector로 학습한 결과를 보여준다.

(1) Syntatic 문법 유추
corpus가 클수록 성능이 꾸준히 증가함을 알 수 있다. 이는 말뭉치가 클수록 더 좋은 통계 정보를 얻을 수 있기 때문이다.
(2) Semantic 의미 유추
의미 유추 문제에서는 Wikipedia처럼 작고 특화된 corpus에서 성능이 더 좋음을 확인할 수 있다. 의미 유추 문제의 경우 도시나 국가와 관련한 문항이 많은데 Wikipedia는 그런 항목들을 잘 담고 있다. 그러나 Gigaword는 뉴스 기반의 corpus로, 업데이트가 없어 정보가 오래되었을 수 있다.
5.3 Runtime
전체 학습 시간은 크게 두 단계로 나뉜다.
| 순서 | task | 조건 | 학습 시간 |
| 1 | X 행렬 생성 (단어쌍의 등장 횟수 계산) | - corpus : 60억 토큰 - 단어 수 : 40만 개 - window size : symmetric 10단어 |
85분 |
| 2 | 모델학습 | - vector dimension : 300 - core : 32개 |
반복 1회당 약 14분 |
5.4 Comparison With Word2Vec
GloVe와 Word2Vec을 비교해보자. corpus, 단어 수, vector dimension, window size를 모두 동일하게 설정하고 비교하였다.
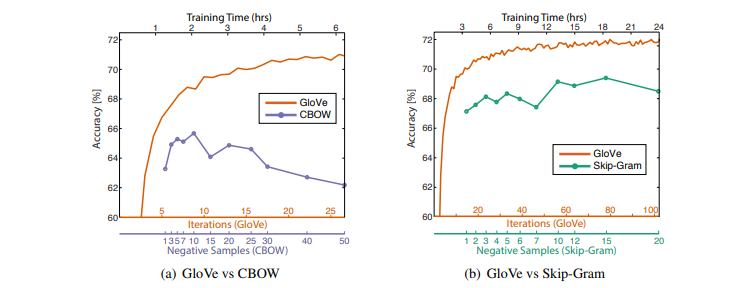
같은 조건에서 학습했을 때, GloVe는 항상 Word2Vec보다 더 나은 성능을 보여주었다. 더 빠르게 수렴하고, 최종 성능 또한 높다.
6. Conclusion
GloVe 모델은 새로운 global log-binary regression 모델로서, 단어 유추(word analogy), 유사도 측정(word similarity), 개체명 인식(NER) 등 다양한 자연어 처리 작업에서 다른 모델들보다 outperformance를 보여준다.

