1. Introduction
논문 이전의 NLP 분야에서는 단어를 원소적인(atomic)한 객체로만 봐 왔다. 이러한 방식은 단순하고 효율적이며, 대용량 데이터에서 좋은 성능을 낼 수 있어 빈번하게 사용되어 왔다.
그러나 단어 간 유사성 정보를 반영하지 못했다. one-hot encoding 방식이 단어의 의미를 벡터에 담지 못하고, 고차원의 sparse한 vector만 생성하여 단순하지만 데이터가 적거나 희소한 경우 성능이 급격히 저하되는 문제가 있었다.
따라서 이 논문에서는 이러한 한계점을 개선하고 더욱 진전된 기술을 소개하고자 하였다. 핵심 목표는 아래와 같다.
1. 수십억 개의 단어와 수백만 개의 어휘를 포함한 대규모 데이터셋으로부터 고품질의 단어 벡터를 효율적으로 학습할 수 있는 모델 제안
2. 기존보다 훨신 간단하면서도 빠른 학습이 가능한 새로운 모델 구조 제안 (CBOW, Skip-gram)
3. 단어 벡터들이 가지는 유사성을 거리뿐만이 아니라 다양한 차원에서 계산. 즉 선형적 의미 관계를 보존하는 구조 개발
4. 문법적(syntatic), 의미적(semantic) 규칙을 동시에 평가할 수 있는 새로운 데이터셋 구축 및 성능 검증
5. 학습 데이터의 크기와 벡터 차원 수에 따라 성능과 효율성이 어떻게 달라지는지 분석
정리하면 간단하고 계산 효율적인 모델인 CBOW와 Skip-gram을 통해 단어의 의미를 잘 반영하는 모델 구조를 제안하는 것이 핵심이다.
2. Previous Work.
먼저 기존의 모델들을 살펴보자.
2.1 N-gram Laguage Model
일련의 단어가 주어졌을 때, 해당 단어들 뒤에 나올 단어를 통계적으로 추측하여 출력하는 모델이다. 카운트에 기반한 통계적 접근을 사용하는 SLM(Statistical Language Model)의 일종이라고 할 수 있다.
이전에 등장한 모든 단어를 고려하는 것이 아니라 일부 단어만 고려하는 접근 방법을 사용한다. 이때 며 개의 단어를 볼 것인지 개수를 정하기 위한 기준을 위해 사용하는 것이 n-gram이다. n-gram에서 n은 연속적인 단어의 나열을 의미하며,코퍼스에서 n개의 단어 뭉치 단위로 끊어서 이를 하나의 토큰으로 간주한다.
| 예시 문장 | An adorable little boy | |
| 단어 개수 (n개) | 이름 | 예시 |
| n = 1 | unigrams | an, adorable, little, boy, is, spreading, smiles |
| n = 2 | bigrams | an adorable, adorable little, little boy, boy is, is spreading, spreading smiles |
| n = 3 | trigrams | an adorable little, adorable little boy, little boy is, boy is spreading, is spreading smiles |
| n >= 4 | n-gram | an adorable little boy, adorable little boy is, little boy is spreading, boy is spreading smiles |
학습 코퍼스를 통해 단어들 뒤에 각 단어가 나올 확률을 계산하여 학습하고, 주어진 N개 단어에 대하여 조건부 확률로 뒤에 등장할 가능성이 가장 높은 단어를 계산하여 결과로 출력한다. 이때, n을 크게 잡으면 모델의 성능을 높일 수 있지만, 동시에 현실 데이터에서 해당 n-gram을 카운트할 수 있는 확률이 적어지므로 희소 문제가 발생할 수 있다. 따라서 적절한 n을 선택하는 것이 중요하다. 앞서 언급한 trade-off 문제로 인해 정확도를 높이려면 n은 최대 5를 넘게 잡아서는 안 된다고 권장하고 있다.
n-gram은 앞의 몇 개의 단어만 보다 보니 의도하고 싶은 대로 문장을 끝맺지 못하는 경우가 발생한다. 앞 부분과 뒷 부분의 문맥이 전혀 연결되지 않는 경우도 생길 수 있다. 결론적으로, 전체 문장을 고려한 언어 모델보다 정확도가 떨어질 수 있다.
2.2 NNLM (Neural-Network Language Model, Feedforward Neural Language Model)
NNLM은 n-gram의 희소 문제를 워드 임베딩으로 해결해 단어의 순서를 보다 정확히 예측할 수 있도록 한 모델이다. 언어 모델이 단어의 의미적 유사성을 학습할 수 있도록 설계해 훈련 코퍼스에 없는 단어 시퀀스에 대한 예측이라도 유사한 단어가 사용된 단어 시퀀스를 참고하여 보다 정확한 예측을 할 수 있다.

NNLM은 총 4개의 레이어로 이루어진 인공신경망이다. NNLM은 n-gram 언어처럼 다음 단어를 예측할 때, 앞의 모든 단어를 참고하는 것이 아니라 정해진 개수의 단어만을 참고한다. 이 범위를 윈도우(window)라고 하는데, 여기서 윈도우의 크기는 n으로 표현하며 입력층에 n개의 one-hot vector가 입력된다.
Output layer에는 정답에 해당되는 단어의 one-hot vector가 있는데, 모델이 예측한 값의 오차를 구하기 위해 레이블로 활용된다. 그리고 Hidden layer에서 오차로부터의 손실 함수를 사용해 학습이 이루어진다.
내부 매커니즘을 순서대로 따라가보자.

Input layer에 입력된 입력 벡터는 다음 층은 projection layer를 통과한다.
projection layer에서 가중치 행렬과의 곱셈이 이루어지는데, 입력 벡터가 one-hot vector이기 때문에 가중치 행렬 W와의 곱은 W 행렬의 i번째 행을 그대로 읽어오는 것(look up)과 동일하다. 따라서, 이 작업을 룩업 테이블(lookup table)이라고 한다.
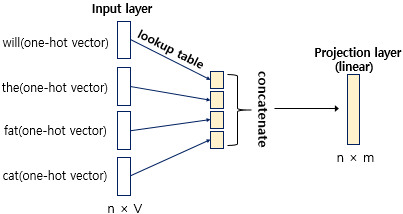
룩업 테이블 작업을 거친 모든 임베딩 벡터들은 연결(concatenate)되어 은닉층을 지나간다. 은닉층에서는 연결된 벡터를 가중치와 곱해 비선형 함수(tanh, ReLU 등)를 적용한다. 즉, 해당 문맥에서 중요한 특징을 파악한다.
은닉층의 출력은 출력층으로 향한다. 출력층에서 가중치를 곱해 선형으로 변환한 후, 활성화 함수로 softmax 함수를 사용한다. 벡터는 소프트맥스 함수를 지나면서 각 원소가 0과 1사이의 값을 가지게 되며, 합이 1이 되는 상태로 바뀐다. 즉, 각 원소가 가지는 값은 해당 원소가 정답이 될 확률을 의미한다. 여기서 확률이 가장 높은 단어를 선택하게 된다.
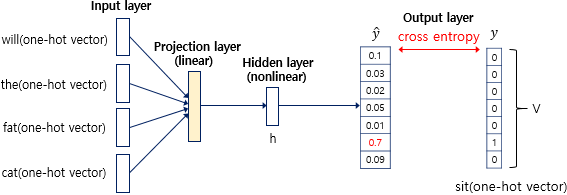
이렇게 예측된 값과 실제 정답 단어를 비교해서, 얼마나 틀렸는지를 cross-entropy로 계산한다. 이 오차를 기반으로 역전파(backpropagation)으로 학습을 진행한다.
NNLM은 단어를 표현하기 위해 임베딩 벡터를 사용하여 단어의 유사도를 계산할 수 있다. 이를 통해 n-gram에서 발생했던 희소 문제(sparsity problem)을 해결하였다. 그러나 한계 또한 존재한다. n-gram 모델과 마찬가지로 이전의 모든 단어를 참고하는 것이 아니라 정해진 n개의 단어만을 참고할 수 있다. 그리고 n-gram에 비해 훨씬 더 많은 연산을 필요로 하기 떄문에 느리다는 문제가 있다.
2.3 RNNLM (Neural-Network Language Model, Feedforward Neural Language Model)
앞서 n-gram과 NNLM은 고정된 개수의 단어만을 입력으로 받아야 한다는 단점이 존재했다. 하지만 시점(time-step)이라는 개념이 도입된 RNN으로 언어 모델을 만들면 입력의 길이를 고정하지 않을 수 있다. 이러한 RNN으로 만든 언어 모델을 RNNLM이라고 한다. RNNLM은 단어를 순차적으로 처리하면서, 앞의 문맥 정보를 기억해 다음 단어를 예측한다.
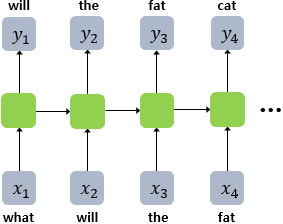
RNNLM은 예측 과정에서 이전 시점의 출력을 현재 시점의 입력으로 둔다. 결과적으로 세 번째 시점에서의 단어 fat은 앞서 나온 what, will, the라는 모든 시퀀스를 반영해 결정된 단어인 것이다.
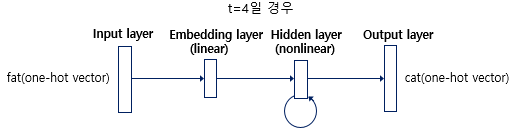
RNNLM의 구조는 위와 같다. 총 4개의 레이어로 이루어진 인공 신경망이다. t(time-step)이 4일 경우, 4번째 입력 단어의 one-hot vector가 input layer에 입력된다. embedding layer에서 입력 벡터와 그 이전의 모든 단어를 숫자 벡터로 변환하고, output layer에서 어떤 단어가 다음에 올지 확률을 예측한다. 예측과 정답의 차이인 손실(loss)를 구해 이것을 중리도록 가중치를 업데이트 하면서 학습한다.
RNNLM은 NNLM에 비해 연산량이 작아 계산 속도가 비교적 빠르지만, 많은 양의 데이터를 학습하기에는 여전히 느린 속도를 보인다.
3. Model Architectures
3.1 Distributed representation
1000개의 단어가 있을 때, 'dog'라는 단어가 4번째 인덱스에 위치한 단어라고 가정해보자. 분산 표현은 아래와 같이 벡터를 표현한다.
e.g. dog = [0.2, 0.3, 0.5, 0.7, 0.9 ... 0.2]
단어의 의미를 다차원 공간에 분산하여 벡터화 시키는 방식이다. 이러한 분산 표현을 이용하면 유사한 단어끼리 비슷한 벡터로 표현되며, 단어 간 의미 관계를 수치적으로 계산할 수 있다. 이때 분산 표현을 이용하여 단어 간의 의미적 유사성을 벡터화 하는 것을 word embedding 이라고 하고, 본 논문에서는 neural net을 학습시키기 위해 분산 표현을 사용한다.
3.2 Computational Complexity
모델 학습에 앞서 computational Complexity(계산 복잡도)를 정의해야 한다. 이때 계산 복잡도란, 모델을 완전히 학습 시키는 데에 필요한 파라미터 수를 의미하며, 계산 복잡도를 최소화하면서 정확도를 최대화 하는 것이 본 논문의 목표이다.

E : 학습 시 에폭의 수 (3-50)
T : Training Set에 있는 단어의 수
Q : 추후 모델 architecture에 의해 결정되는 부분
3.3 CBOW (Continuous Bag-of-Words) Model
CBOW는 주변에 있는 단어들을 입력으로 중간에 있는 단어들을 예측하는 방법이다.

중심 단어를 예측하기 위해서 앞, 뒤로 몇 개의 단어를 볼지를 결정해야 하는데 이 범위를 윈도우(window)라고 한다. 예를 들어 'The fat cat sat on the mat'이라는 문장에서 중심 단어가 sat, 윈도우가 2라면 앞의 두 단어인 fat, cat과 뒤의 두 단어인 on, the를 입력으로 사용한다. 즉, 윈도우(window)의 크기가 n개이면 실제 중심 단어를 예측하기 위해 참고하는 주변 단어의 개수는 2n개인 것이다.

윈도우의 크기가 정해지면 윈도우를 옆으로 움직여서 주변 단어와 중심 단어의 선택을 변경해가며 학습을 위한 데이터셋을 만드는데, 이를 슬라이딩 윈도우(sliding window)라고 한다.

CBOW의 신경망을 도식화하면 위와 같다. 입력층에 사용자가 정한 윈도우 크기 범위 안에 있는 주변 단어들의 one-hot vector가 들어가고, 출력층에는 예측하고자 하는 중간 단어의 one-hot vector가 레이블로 들어간다.
입력층을 통과한 벡터는 projection layer로 넘어간다. projection layer에서는 입력 벡터들(모든 주변 단어 벡터들)을 입력 가중치 행렬과 곱하고, 평균을 내서 하나의 벡터로 만든다. 이때 만들어진 벡터를 문맥 벡터(context vector)라고 한다.
문맥 벡터는 output layer에서 출력 가중치 행렬과 곱해진다. 그 결과에 softmax를 적용해 전체 단어 사전에 대한 확률 분포를 계산한다. 즉, 모델이 context vector를 보고 모든 단어가 중시일 확률을 예측한다. 가장 확률이 높은 단어를 예측값으로 두고, 실제 중심 단어와의 차이를 줄이는 방향으로 학습한다.
이러한 아키텍처는 NNLM과 유사하지만, hidden layer가 제거되면서 projection layer가 모든 단어와 공유된다. 또한, 전체 word vector의 평균값을 사용하기 때문에 단어의 순서가 projection에 영향을 주지 않는다.
CBOW 아키텍처의 training coomplexty는 아래와 같다.
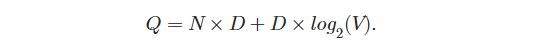
3.4 Continuous Skip-gram Model
continuous Skip-gram Model은 CBOW와 반대로 중심 단어를 통해 주변 단어를 예측한다.
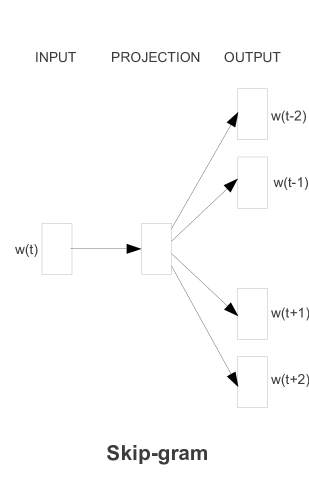
윈도우(window)의 크기가 2일 때, 데이터셋은 아래와 같이 구성된다.
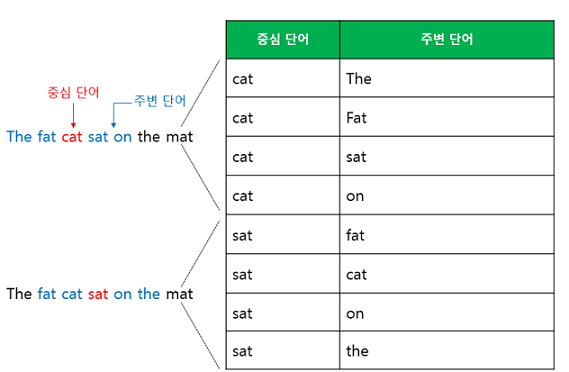
중심 단어가 cat이고, n=2일 때, 중심 단어에 대한 주변 단어는 The, fat, sat, on이 된다.

Skip-gram의 인공신경망을 도식화하면 위와 같다. 입력으로 예측에 이용할 중간 단어의 one-hot vector가 들어가고, output layer에는 예측하고자 하는 2n개의 주변 단어의 one-hot vector가 레이블로 들어간다. 중심 단어에 대해서 주변 단어를 예측하기 때문에 투사층에서 벡터들의 평균을 구하는 과정은 없다.
일반적으로 Skip-gram이 CBOW보다 성능이 좋다고 알려져 있다.
Skip-gram 아키텍처의 training complexity는 아래와 같다.
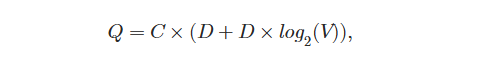
4. Results
4.1 Task Description
본 논문에서는 유사한 단어쌍을 수집하고 조합해 의미적/문법적 질문 9종류를 만들고, 벡터 연산 결과에서 가장 가까운 단어와 정답 단어가 정확히 같아야만 정답으로 처리해 품질을 측정했다.
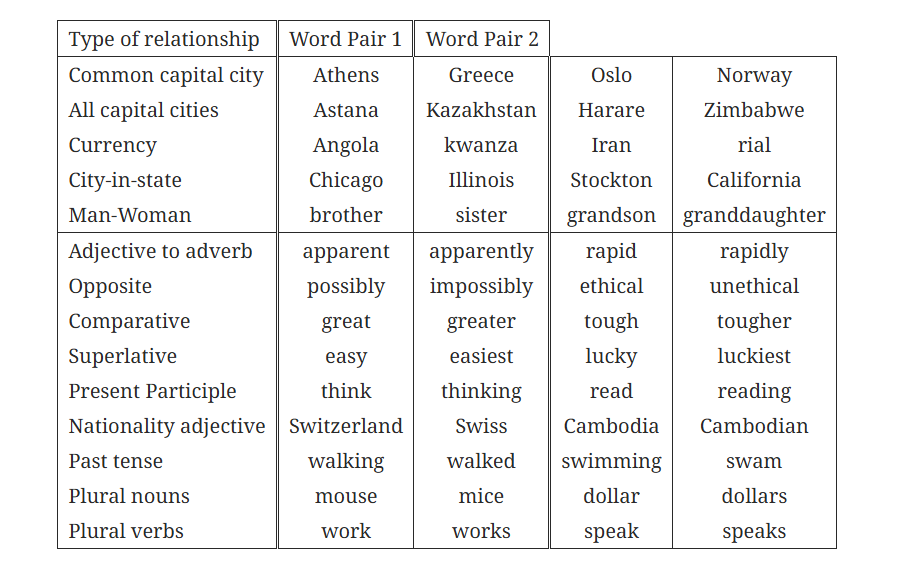
그 결과는 위와 같다.
4.2 Maximization of Accuracy
본 논문에서는 Google News 말뭉치를 사용해 모델의 학습을 진행했다. 약 60만 개의 단어들이 존재하는데, 가장 자주 등장하는 단어들을 기준으로 10만 개의 단어들을 학습에 사용했다.
그 결과, 단어를 표현하는 벡터의 차원을 늘릴수록 정확도는 늘어났지만, 동시에 계산량도 함께 늘어나기 때문에 적절한 조절이 필요했다.
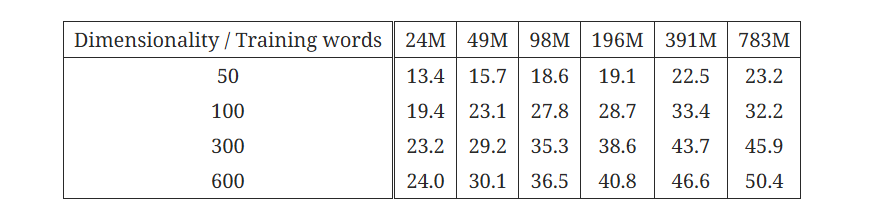
차원을 증가시키기만 하거나 데이터셋을 늘리기만 하는 것은 정확도의 증가율이 점점 낮아졌다. 차원과 데이터셋을 동시에 늘렸을 때 정확도의 증가폭을 늘릴 수 있었다.
4.3 Comparison of Model Architectures
다른 모델들과의 비교 평가를 진행하였다. 정확한 평가를 위해 표현되는 단어의 차원과 학습에 사용되는 데이터셋의 규모를 모두 고정시켰다. 그 결과는 아래와 같다.

RNN은 주로 문법적인 측면에서 좋은 성능을 보인다. NNLM은 전반적으로 RNN보다 훨씬 우수한 성능을 보인다.
CBOW는 문법적 태스크에서 NNLM보다 더 좋은 성능을 보이지만, 문맥적 태스크에서 NNLM과 비슷한 성능을 낸다. Skip-gram은 문법적 태스크에서는 CBOW에 비해 약간 떨어지는 성능을 보이지만, 의미적 태스크에서는 모든 모델 중 가장 뛰어난 성능을 보인다.
5. Conclusion
본 논문을 통해서 저자는 여러 모델을 통해서 얻은 다양한 단어 벡터 표현을 확인하였다. 단어의 의미를 반영한 분산 표현을 효율적으로 학습할 수 있는 두 가지 모델, CBOW와 Skip-gram을 제안하였다. 기존의 one-hot 방식이나 신경망 언어 모델에 비해 훨씬 간단한 구조이면서도, 대규모 말뭉치에서도 빠르게 학습이 가능하고, 단어 간의 의미적, 문법적 관계를 잘 반영하는 벡터를 생성할 수 있다는 점에서 큰 의의를 가진다.
결과적으로, Word2Vec은 계산 효율성과 표현력 사이의 균형을 잘 잡은 모델로 이후의 다양한 NLP 모델의 핵심 기반으로 자리잡았다.
'Paper review' 카테고리의 다른 글
| [paper review] Semantic Data Lineage and Impact Analysis of Data Warehouse Workflows (1) | 2025.05.06 |
|---|---|
| [paper review] GloVe: Global Vectors for Word Representation (0) | 2025.03.29 |

