1.1 Overview of Data Lineage and Provenance
# Data Lineage 란
'데이터가 어디에서 왔고 어떻게 유래되었는지'를 추적하는 개념으로, 과학 분야에서는 provenance라는 용어를 사용
# Data Lineage는 왜 중요할까?
신뢰성, 정확성, 무결성 확보에 필수적이다. 머신러닝, 데이터 웨어하우스, 비즈니스 인텔리전스 등에서는 데이터가 어떻게 만들어졌는지를 추적하지 않으면 결과도 믿기 어렵기 때문
# 적용 분야
- Data Warehouses : ETL(추출-변환-적재) 과정을 통해 구성된 데이터 저장소
- Curated Databases : 수작업으로 정제/갱신된 데이터베이스
# Data Lineage의 두 가지 표현 방식
- 워크플로우 수준 (Coarse-grainde lineage)
큰 단위의 처리 단계(프로그램, 작업 순서 등)를 중심으로 표현하며, 데이터가 어떻게 흘러갔는지 전반적인 흐름을 보여줌
- 데이터 항목 수준 (Fine-grained lineage)
컬럼, 행, 튜플 등 아주 세부적인 수준에서 추적하며, 각 데이터 항목이 어떤 단계를 거쳐 도출되었는지 상세하게 설명
# Data Lineage를 바라보는 관점
- Why Lineage (왜)
왜 이 데이터가 결과에 포함되었는가? 라는 조건과 맥락을 설명한다.
- How Lineage (어떻게?)
어떤 연산으로 이 데이터가 만들어졌는가?라는 변환 로직을 설명한다.
- Where Lineage (어디서)
이 데이터가 어디서 왔는지 데이터 소스와 컬럼 매핑을 설명한다.
# Data Lineage의 계산 방식
Data Lineage란 이 데이터가 어디서 왔고, 어떻게 만들어졌으며, 왜 포함되었는가를 추적하는 것이다. 이를 위해 SQL 쿼리를 해석하거나, 데이터 변환 함수 혹은 조건문을 분석한다.
본 논문에서는 Data Lineage를 계산하기 위한 두 가지 방식을 설명한다.
- 비주석 방식 (Non-annotation)
원본 데이터를 변환 함수에 적용해 결과 데이터를 얻는 방식으로, 원본 데이터가 필요하다. 시스템에 영향을 주지 않고 빠르게 도입이 가능하다는 장점을 지닌다.
> 변환된 결과만 보고, 메타데이터와 쿼리 해석만으로 출처 추론
> 빠르고 가볍지만 주석 방식에 비해 정확도가 낮을 수 있음
- 주석 방식 (annotation)
데이터 변환 중 추가 메타데이터(출처 등)를 함께 저장하는 방식으로, 초기 함수 수정 및 저장 공간이 필요하다. 원본 데이터 없이도 lineage를 분석할 수 있다.
> 데이터 변환 시 각 데이터에 출처 정보를 함께 기록하여 추론
> 정확하지만 계산/저장 비용이 큼
본 논문에서는 두 가지 방식 중 비주석 방식을 채택하였다.
- 메타데이터
> 테이블 이름, 칼럼 이름
> 쿼리 구조
> 스키마 구조
> ETL 프로세스 정의
# Motivating Example
금융 산업의 데이터 웨어하우스에서 발생하는 데이터 계보 및 데이터 영향도 문제의 예시로 네 개의 SQL 쿼리와 네 개의 소스 테이블을 사용하는 데이터 적재 및 변환 시나리오를 구성하였다.


- JOB1 : DW로의 데이터 로딩 담당
- JOB2 : 로딩된 데이터의 변환 및 비정규화 수행
- JOB1을 수행하기 위해 Query 1, Query 3 설계
- JOB2를 수행하기 위해 Query 2, Query 4 설계
쿼리 예시는 아래와 같다.
(SQL Query 4)
INSERT INTO LOAN_SUMMARY (Period_Date, Agreement_Nbr, Agreement_State, Principal_Amt)
SELECT T3.Balance_Date, T4.Agreement_Nbr, T4.Agreement_State, T3.Balance_Amt
FROM AGREEMENT T4
JOIN BALANCE T3 ON T4.Agreement_Nbr = T3.Agreement_Nbr
WHERE T4.Agreement_Type = ‘L’
AND T4.Agreement_State = 2
AND T3.Balance_Date = DATE-1
이러한 쿼리들을 통해 소스 테이블과 타깃 테이블, 작업 간의 의존 관계를 추출할 수 있으며 이를 방향 그래프(directed graph)로 표현할 수 있다.
이때 노드는 테이블, 작업, 쿼리 등의 구조나 구성요소르 의미하고 엣지(edge)는 소스 테이블에서 타깃 테이블로의 데이터 흐름을 나타낸다.
그래프의 방향성은 데이터가 어디서부터 어디로 흘러가는지를 보여주며, 이를 통해
- Data Lineage : 타깃 > 소스 방향의 서브 그래프 조회
- Data Impact : 소스 > 타깃 방향의 서브 그래프 조회
가 가능하다.
이때 주의할 점은, coarse-grain 수준의 table-query 그래프만으로는 어떤 테이블에서 실제로 데이터가 이동했는지, 혹은 단지 필터링이나 조회용으로만 사용되었는지 알기 어렵다.
예를 들어 ACCOUNT_STATE나, LOAN_TYPE 테이블은 AGREEMENT로 데이터를 이동시키는 것처럼 보이지만, 실제로는 필터링 용도로만 사용되고 데이터는 저장되지 않는다.
따라서 이런 세부 사항을 확이하기 위해서는 fine-grain (컬럼/연산 단위) 분석까지 내려가야 정확히 알 수 있다.
# Motivating Example 요약/정리
- (예시) 금융회사에서 데이터 분석을 위해 DW에 데이터를 모으고 있는데, 이때 SQL 쿼리를 통해 데이터가 이 테이블에서 저 테이블로 옮겨지고, 가공되고 있다.
- Query 1,3은 JOB1을 수행하는데, ACCOUNT와 LOAN 데이터를 가공해서 AGREEMENT 테이블로 저장하고 있다. 이때, 몇몇 테이블은 단순히 필터링만 하고, 실제 데이터는 저장되지 않는다.
- Query 2,4는 JOB2를 수행하는데, AGREEMENT 테이블과 BALANCE 테이블을 합쳐서, DEPOSIT_SUMMARY, LOAN_SUMMARY 테이블로 데이터를 넣는다.
- 여기서, 이 시스템이 복잡해짐녀 데이터가 어디서 왔는지 혹은 어떤 데이터를 바꾸었을 때 어디에 영향이 가는지 알기 어려워진다. 따라서, Data Lineage와 Data Impact를 분석하고자 하는 것!
- 예를 들면, LOAN 테이블의 한 값이 바뀌면, 나중에 어떤 요약 테이블에 영향이 가지?, DEPOSIT_SUMMARY에 있는 이 값은 원래 어디서 왔지? 와 같은 질문에 대답할 수 있다.
- 그렇다면 이것을 어떻게 추적할 수 있는가? SQL 쿼리를 분석해서 그래프처럼 만들 수 있다.
> 노드(Node) : 테이블, 쿼리, 작업(job)
> 엣지(Edge) : 데이터가 흐르는 방향
ACCOUNT → AGREEMENT → DEPOSIT_SUMMARY
LOAN → AGREEMENT → LOAN_SUMMARY
- 여기서 주의해야 할 점은, 예시에서 ACCOUNT_STATE와 같은 테이블은 실제로 데이터가 들어간 건 아니고, 그냥 조건 필터로 사용되었다. 따라서 진짜 데이터를 가져온 건지 단순히 조건으로 쓴 건지를 아려면 더 정밀한 수준(fine-grain)의 분석이 필요하다.
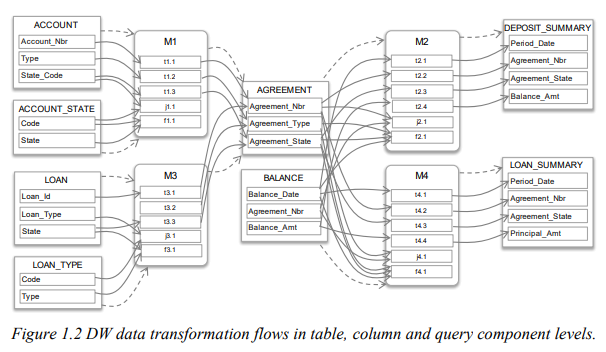
fine-grain 수준에서는 위와 같이 SQL 쿼리들을 더 정밀하게 분석해서 어떤 테이블의 어떤 칼럼이 어디의 어떤 칼럼으로 갔는지까지 파악이 가능하다. 이를 통해 더 정확한 Data Lineage와 Impact Analysis가 가능하다.
먼저 SQL 쿼리를 분석해서 입력 테이블과 출력 테이블 사이의 관계 그래프를 만들 수 있다. 이 그래프는 데이터가 어떻게 가공되었는지까지 알려주지는 않지만, 어떤 칼럼에서 어떤 칼럼으로 어떤 필터 조건에 따라 데이터가 흘렀는지 알 수 있다.
# Overall Architecture and Methodology
전체 시스템의 작동 구조는 아래와 같다.
1. 메타데이터 수집
- 다양한 시스템에서 DW 흐름 관련 메타데이터 수집 (ETL, 쿼리, 보고서 등)
- 데이터 흐름 이해의 기초 자료가 된다.
2. SQL 파싱
- 맞춤형 문법 기반으로 SQL을 파싱한다. (GoldParser + XDTL 사용)
- SQL의 전체적인 구조를 파악한다
3. 파싱 트리 매핑
- 파싱된 결과에서 의미있는 부분만 추출한다 (문법 규칙 기반)
- 중요한 표현만 걸러내는 단계
4. 쿼리 해석
- 별칭, 서브쿼리, 변수 등을 해석해 쿼리 구조를 완전하게 분석한다.
- 실제 흐름 복원
5. 가중치 계산
- 조인, 필터 등 SQL 표현의 의미를 정량화한다.
- 데이터 흐름의 중요돌를 평가하는 과정
6. 추론 엔진
- 위의 가중치를 기반으로 impact와 Lineage를 추론한다.
- 어떤 요소가 어디에 영향을 주는지 계산한다.
7. 그래프 저장
- 의존성 그래프를 DB에 저장 (노드 간 방향 및 가중치 포함)
- 계보 및 영향도 시각화의 기반
8. 시각화 & 분석
- 그래프 기반 분석 결과를 웹 UI로 제공
- 사용자 인터페이스로 결과 활용 가능

> 파란색 : 데이터 수집을 위한 컴포넌트
> 빨간색 : 실제로 데이터를 처리하는 컴포넌트 (SQL 파서, 쿼리 분석기 등)
> 하얀색 : 데이터를 직접 처리하지 X, 시스템 지원 컴포넌트
#1. Metadata Database

# How- MOF(Meta Object Facility) 구조를 따름> M0 ~ M3까지 계층적인 모델링 구조 (M0 = 실제 데이터, M1 = 모델, M2 = 메타모델, M3 = 메타메타모델)
- EAV (Entity-Attribute-Value) 모델 사용> 열이 정해져있지 않고, 데이터를 엔티티, 속성, 값으로 표현> 매우 다양한 종류의 데이터를 유연하게 저장 가능
# Why
- 데이터 저장 시 스키마를 미리 정하지 않아도 된다.
- 데이터가 계속해서 바뀌는 환경에서 유리하다
- RDF (Resourse Description Framework)처럼 Semantic한 표현이 가능하다.
- 다양한 포맷으로 내보낼 수 있다.
# What Can Do
- 쿼리를 날릴 대 동적으로 의미를 해석할 수 있다
- 간단한 논리 추론 (상속 관계, 유효성 검사 등)도 SQL로 처리할 수 있다.
- Jena 같은 외부 추론 엔진과 연결해 복잡한 추론도 가능하다.
(정리) 메타데이터 데이터베이스는 데이터를 설명하는 데이터를 저장하는 구조 - 이때, 데이터를 자유롭게 저장할 수 있도록 EAV 방식을 사용함
(일반적인 구조)
| 계좌번호 | 잔액 | 날짜 |
(EAV 방식)
| Entity | Attribute | Value |
| 계좌1 | 잔액 | 10,000 |
| 계좌1 | 날짜 | 2023-01-01 |
위와 같은 방식은 속성이 늘어나도 테이블을 바꿀 필요가 없기 때문에 다양한 정보를 유연하게 다룰 수 있다.
- 데이터를 계층적으로 정리할 수 있도록 MOF 구조를 사용함. 4개의 추상적 계층으로 나뉘어 있으며, 각 계층은 서로 다른 정보의 수준을 설명한다.
| 계층 | 의미 | 예시 |
| M3 | 설명의 설명 | 모든 테이블은 속성과 타입을 가져야 한다. |
| M2 | 설명의 설계도 | ACCOUNT 테이블에는 '잔액'(속성)이 있고, '숫자'(타입)이다. |
| M1 | 실제 설계 | 실제 데이터 구조에 ACCOUNT 테이블과 BALANCE 열이 있다. |
| M0 | 실제 데이터 | 계좌1은 10,000원이 있다. |
즉 위로 갈수록 더 추상적이고 설계적인 정보이며, 아래로 내려올수록 현실의 실제 데이터가 된다. 데이터에 대한 정보와 그 정보에 대한 정보의 방식으로 계층적으로 저장된다.
이때, 메타데이터 데이터베이스는 단순히 저장만 하는 게 아니라 A 데이터는 B 데이터와 연결되어 있다와 같은 논리적 추론이 가능하다.
#2. Metadata Model
앞서 본 멭타데이터 데이터베이스에서 데이터를 유연하게 저장했다면, 저장할 정보를 설계하는 것이 메타데이터 모델이다.
| 모델 | 설명 | 예시 |
| 관계형 데이터베이스 모델 | 데이터베이스에 있는 칼럼, 뷰, 데이터 타입을 저장 | user 테이블에 id, name과 같은 칼럼을 저장 |
| ETL 모델 | 데이터를 옮기고 가공하는 이동 과정을 정리한다 | 데이터 복사, 필터링, 다른 테이블에 저장하는 단계들이 어떻게 이어지는지 정리 |
| 리포트 모델 | 데이터가 어떻게 요약되고 보여지는지 저장 | 월별 매출 리포트가 있고, 그 안에 지역/제품/매출액과 같은 차원과 지표가 있다. |
| 매핑 모델 | 서로 다른 모델 사이의 연결 관계나 계산 방식을 저장한다. | 리포트에 있는 총 매출은 DB의 price, quantity에서 계산된다. |
본 논문의 시스템에서는 이 모델들을 바꾸더라도 실제 데이터베이스 구조(스키마)를 바꿀 필요가 없기 때문에, 유연한 사용이 가능하다. (소프트 모델)
모든 모델들은 공통된 메타데이터 데이터베이스에 저장되고, 필요할 때마다 이 데이터베이스에서 정보를 가져오거나 해석해서 분석이나 시각화에 사용한다.
예를 들어, 매출 리포트의 한 부분을 파싱한다고 가정해보자.
시스템은 리포트 모델에서 해당 리포트를 찾고, 매핑 모델을 통해서 어떤 SQL 쿼리로 나왔는지 찾고, ETL 모델을 통해서 어떤 ETL 작업을 거쳤는지 추적하고, 최종적으로 어떤 DB 테이블과 칼럼을 썼는지 DB 모델에서 확인한다.
#3. Data Capture, Store and Processing with Scanners
시스템이 메타데이터를 어떻게 수집하고 저장하며 처리하는지 소개한다.
XDTL을 사용해 ETL 작업을 정의하고 관리하는 방법과, Scanner를 통해 외부 시스템에서 메타데이터를 수집해서 저장하는 두 가지 방식으로 나뉜다.
1. XDTL (Extensible Data Transformation Language)
- ETL 전용으로 설계된 XML 기반 스크립트 언어로, ETL 작업을 정의할 때 사용된다.
- 모듈화, 재사용성, 확장성이 뛰어나며 다양한 프로그래밍 언어나 도구들과 연동 가능
- 스크립트를 XML로 저장하거나 DB에 저장할 수 있다. > 쉽게 재사용 가능
- 외부에서 만든 mapping을 참조할 수 있기 때문에 다양한 변환 작업에서 재활용된다.
2. Scanner
- 외부 시스템으로부터 메타데이터를 자동으로 수집하는 프로그램 또는 프로세스
- DB 스키마, SQL 쿼리, ETL 도구의 작업 순서, 매핑, 리포트 툴의 보고서 구조 등을 수집한다.
- 수집한 정보는 미리 정의된 메타모델에 맞춰서 메타데이터 데이터베이스에 저장된다.
쉽게 말해,
외부 시스템 > 스캔 > 변환 (메타모델에 맞추어 정리) > 저장 (메타데이터 DB) 의 과정을 거친다.
#4. Query Parsing and Metadata Extraction (핵심)
SQL 쿼리나 스크립트 안에 숨겨진 데이터 흐름/구조 정보를 자동으로 분석, 추출해 메타 데이터로 변환하는 과정을 소개한다. 데이터 흐름을 처음부터 끝까지 추적하려면 (예를 들어 회계시스템 > 리포팅 시스템) 서로 다른 시스템의 동일하거나 관련있는 객체를 연결하는 과정이 필요하다. 이 연결은 SQL 쿼리, ETL 스크립트, 리포트 구조 안에 들어있는 표현을 파싱하고 이해해야 가능하다.
핵심은 복잡한 SQL 쿼리에서 의미있는 정보를 자동으로 뽑아낸다는 것이다.
1. SQL 쿼리 수집
- 스캐너가 ETL 스크립트, DB 뷰, 프로시저, 리포트 구조 등에서 SQL 쿼리나 표현식을 수집한다.
2. 쿼리 파싱 (문장 구조 분석)
- Java 기반 파서 엔진과 커스텀 SQL 문법(EBNF 형식)을 사용한다.
- 이 문법은 다양한 DB의 SQL 문법을 포함한다. (Oracle, Postgres, MSSQL 등)
- 결과적으로 쿼리를 트리처럼 구조화한다. (SELECT절, FROM절, JOIN 조건, WHERE 조건이 각각 분리됨)
> 마치 언어 문장을 문법 단위로 쪼개서 구조를 분석하는 것과 같다. (주어, 동사, 목적어 등)
## EBNF란? (Extended Backus-Naur Form)
프로그래밍 언어나 쿼리 언어의 문법을 설명할 때 사용하는 표기법으로, 컴퓨터에게 '이 문장은 이렇게 생겼어'라고 규칙을 알려주는 언어이다.
<SELECT column FROM table>과 같은 SQL 쿼리가 있다고 할 때, 이걸 EBNF로 표현하면
SelectStmt ::= "SELECT" ColumnList "FROM" TableName
ColumnList ::= ColumnName | ColumnName "," ColumnList
- SelectStmt(SELECT 문)는 "SELECT" 키워드 다음에 ColumnList가 오고, "FROM" 다음에 TableName이 온다
- ColumnList는 하나 이상의 ColumnName을 쉼표로 구분해서 쓸 수 있다
와 같이 표현할 수 있다. (SQL parser를 만들 때 사용되는 방식임)
3. 파싱 결과를 Parse Tree로 만들기
- 각 쿼리 요소가 트리 구조로 정리된다.
<Select> → SELECT
├─ <Columns> → a.name, b.salary
├─ <From> → emp a
├─ <Join> → dept b ON a.dept_id = b.id
└─ <Where> → b.location = 'Seoul'
4. Parse Tree Mapper가 의미있는 정보로 바꾼다.
- 이 트리를 읽어서 의미있는 정보를 추출한다.
- 이때, JSON으로 정의된 규칙 세트를 사용해 다음을 뽑는다.
> stopwords : 파싱을 초기화하거나 새로운 구간 시작을 알린다.
> mapwords : 특정 패턴을 실제 의미로 매핑한다. (예 : From > Source, Where > filter)
> tagwords : 중요한 요소(테이블, 컬럼명, 상수 등)를 태깅한다.
{"map": "Source", "token": "FROM", "rule": "<From>"}
{"map": "FilterCondition", "token": "WHERE", "rule": "<Where>"}
5. SQL Query Resolver가 최종 의미를 정리한다.
[Source] emp, dept
[JoinCondition] a.dept_id = b.id
[FilterCondition] b.location = 'Seoul'
[SelectedColumns] a.name, b.salary
- 이 쿼리가 어떤 테이블에서 어떤 조건으로 데이터를 가져오는지 완벽히 이해 가능
정리하면 이 과정은 SQL 쿼리를 문법적으로 분석해서(parse), 그 구조를 트리(tree) 형태로 표현한 다음, 그 트리를 의미있는 정보로 매핑(mapping)하는 과정이다.
#5. Data Transformation Weight Calculation
데이터가 SQL문을 통해 변형되거나 필터링될 때, 어느 컬럼이 얼마나 영향을 주고 있는지 정량적으로 평가하기 위해 가중치를 계산한다. 단순히 어떤 칼럼이 사용되었는가를 넘어서 사용된 방식이 얼마나 복잡했는지를 고려한다. 이때 이 값은 0-1 사이의 값으로 표현되며, 확률처럼 해석이 가능하다.
이러한 가중치 정보를 통해 Data Lineage 추적을 더 정밀하게 할 수 있고, 중요한 컬럼이 무엇인지 파악할 수 있으며 데이터 흐름의 메타데이터 기반 분석이 가능하다.
1. SQL 표현식 파싱
- 어떤 컬럼이 사용되었는지
- 어떤 함수가 적용되었는지
- 상수/문자열 등은 얼마나 포함되었는지
를 파싱한다.
2. 각 요소의 개수를 세어 점수화
- 예를 들어, 칼럼 수 1, 함수 수 1, 문자열 수 0과 같이 값을 카운트 했다면 이 값으로 비율 기반 가중치(W)를 계산한다.
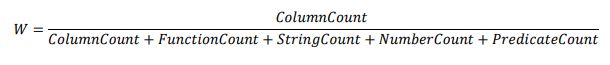
3. 변환 가중치와 필터링 가중치
쿼리에서 컬럼은 크게 두 가지 방식으로 사용된다.
| 변환용 | 데이터를 가공해서 새로운 결과로 만들 때 |
| 필터링용 | WHERE 조건 등에서 걸러낼 때 |
이 두 가지는 용도가 다르기 때문에 각각 따로 가중치를 계산해야 한다.
1. 변환 가중치 Sw (Transformation Weight)
- 이 칼럼이 얼마나 직접적으로 결과에 사용되었는가?를 나타낸다.
- 칼럼을 그대로 가져왔따면 점수가 1에 가깝고, 여러 함수나 조건으로 가공했다면 점점 점수가 낮아진다.
2. 필터링 가중치 Fp (Filter Weight)
- 이 칼럼이 조건문 등에서 얼마나 직접 사용되었는가?를 나타낸다.
- 이것도 마찬가지로 조건문 안에서 직접 사용되었다면 점수 1, 가공되어 사용된다면 점점 점수가 낮아진다.
이 두 가중치 모두 표현식의 구성 요소를 세서 계산한다. 복잡할수록 점수는 낮아지고, 단순할수록 점수는 높아진다.
#6. Rule System and Dependency Calculation (핵심)
앞서 계산한 가중치를 실제로 어떻게 써서 데이터 간의 의존성(lineage, impact)을 판단하고 시각화하는지를 설명한다.
먼저, 데이터 간의 관계를 그래프로 표현한다.
> 노드 : 컬럼이나 테이블, 쿼리 구성요소> 엣지 : 관계 (A>B : A가 B에게 영향을 준다)> 가중치 : 그 영향력의 세기가 얼마인지 보여준다 (앞서 계산한 가중치)
1. Rule 1 : 변환 경로 계산 - GL 그래프 만들기- Sw 가중치 사용- A 칼럼이 변환되어서 B 칼럼이 되었을 때, A>B라는 선을 긋고 거기에 얼마나 직접적으로 영향을 주었는지 점수를 표히한다.

이때, 여러 개의 엣지가 존재한다면 (모두 x>y 방향) 이들을 통합해서 하나의 대표 엣지를 만들어야 한다. 연결된 모든 변환 표현식을 모아 가장 큰 가중치(Sw)를 선택해 e'로 설정하는 것이 첫 번째 규칙이다.
2. Rule 2: 필터 조건 영향도 계산(Impact) - GI 그래프 만들기
- Fp 가중치 사용
- 어떤 필터 조건이 데이터의 어떤 컬럼에 영향을 주는가를 분석해서 Impact Graph를 만들기 위한 규칙

입력 데이터에서 나이 > 30 이라는 필터 조건이 있다고 가정해보자. 이 조건을 만족하는 데이터만 출력 테이블의 salary 칼럼에 들어간다. 이때 나이 필터가 salary 칼럼에 얼마나 영향을 미치는지를 계산하는 영향도 그래프를 만들 것이다.
먼저 필터 조건들과 타겟 칼럼들을 모은다. 그리고 e′라는 새로운 엣지를 만들어서,
- e'.X = p → 필터가 적용된 원본 컬럼
- e'.Y = p' → 영향 받은 결과 컬럼
- e'.M = M → 어떤 매핑 작업인지
- e'.W = 평균 가중치 → 필터들의 영향력을 평균 내서 사용
위와 같이 계산한다. 즉, 필터들이 특정 결과 컬럼에 영향을 미쳤다면, 그 경로를 하나의 엣지로 통합해 그 영향력을 평균 가중치로 표현한다.
3. Rule 3 : 상위 구조로 정보 퍼뜨리기
앞서 살펴본 두 그래프 (GL, GI)는 칼럼 단위로 작성되었다. 하지만 실제 분석에서는 테이블 단위로 변화를 보고싶을 수 있기 때문에, 같은 테이블 안에 있는 칼럼들끼리의 관계를 모아서, 테이블 간 관계로 올리는 작업을 진행한다.
- 먼저 같은 부모(p)를 가진 칼럼들끼리 묶는다. (x1, x2 > 테이블 A)
- 같은 부모를 가진 대상 칼럼들도 묶는다. (y1, y2 > 테이블 B)
- 이미 알고 있는 엣지들을 찾는다. (x1 > y1, x2 > y2)
- 이것을 하나의 상위 엣지 e′로 만든다.
- e′.X=pe'.X = p → 예: 테이블 A
- e′.Y=p′e'.Y = p' → 예: 테이블 B
- e′.M=⋃e.M → 어떤 매핑들이 영향을 줬는지 전부 합침
- e′.W=평균 가중치 → 원래 엣지들의 가중치 평균
이렇게 계산하면 칼럼이 수십 개 때도, 간단히 테이블 단위로 흐름을 볼 수 있고 시각화, 의존도 분석, 영향 분석에서 핵심 요약 정보를 제공할 수 있다.
## 정리
1. 입력 : Query
- 사용자가 쿼리 작성
- 쿼리 분석 후 데이터 흐름 정보 추출
2. Rule System으로 정보 추론
- Lineage 그래프 (GL) 작성
> 칼럼 간의 단순 데이터 흐름 찾음
> 같은 노드 쌍 간 여러 경로가 있다면 가중치 W는 가장 큰 값, 매핑 정보 M은 모두 합침
> 어떤 컬럼이 어떤 컬럼에서 유래했는지 추적
- Impact 그래프 (GI) 작성
> 필터 조건이 컬럼에 어떤 영향을 줬는지 찾음
> 필터 조건 노드를 타깃 칼럼 노드로 연결
> 가중치 W는 필터 조건들의 평균 영향도를 의미
> 어떤 조건문이 어떤 칼럼을 바꿨는지 분석
- 상위 구조 단위로 추론 (테이블/스키마)
> 칼럼 간 연결이 여러 개 있으면 이를 테이블 수준의 연결로 요약
> 같은 부모(테이블, 스키마 등)를 가진 칼럼들을 묶어서 상위 단위의 엣지를 마들어냄
> 가중치는 평균값, 매핑은 전체 합으로 나타냄
> 복잡한 컬럼 흐름을 단순한 테이블 간 흐름으로 요약
3. 왜 하는가?
- 이 값이 왜 이렇게 나왔는지 문제 추적 : Lineage
- 이 칼럼을 바꾸면 어디에 영향이 가는지 임팩트 추척 : Impact
- 어떤 테이블이 중요한지 판단하고 복잡한 흐름을 그래프로 간단히 보여줄 수 있음
#7. Semantic Layer Calculation
Data Lineage 및 영향도 분석 시스템의 Semantic Layer Calculation을 소개한다.
여기서 Semantic Layer란,
> 선택한 노드(칼럼, 테이블 등)에 대해 관련 있는 부분 그래프 (subgraph)만 보여주는 시각화 계층
> 관련 여부는 쿼리의 필터조건이나 전환조건을 분석해서 결정
> 결과적으로 가능성 있는 흐름(Probable flow)만 남기고 의미없는 연결은 제거하거나 흐리게 표시하는 것
기본적인 Lineage/Impact 그래프는 모든 가능한 데이터 흐름을 보여준다. 하지만, 모든 흐름이 실제로 일어나는 것은 아니다. 예를 들어, AGREEMENT 테이블이 ACCOUNT, LOAN 양쪽에서 데이터를 받을 수 있지만, 조건이 다르면 실제로는 각각 다른 경로만 쓰일 수 있게 된다. 그래서 실제 데이터의 흐름을 더 정밀하게 보여주기 위해 Semantic Layer가 도입되었다.
1. 사용자가 특정 노드를 선택한다.
2. 해당 노드에 관련된 쿼리 필터 조건을 확인한다.
3. 이전 노드의 방향과 다음 노드의 방향을 각각 따로 탐색한다.
- 이때, 조건이 겹치는 연결만 따라간다.
4. 필터 조건이 겹치는 노드/엣지만 포함된 subgraph를 생성한다.
5. 나머지 노드는 흐리게 처리하거나 제거한다.
예를 들어,
- AGREEMENT는 ACCOUNT/LOAN 양쪽 데이터를 통합
- DEPOSIT_SUMMARY는 ACCOUNT 기반, LOAN_SUMMARY는 LOAN 기반
- 필터 조건이 다르기 때문에 → 실제 흐름은 둘로 나뉨
- 이를 통해 의미 있는 두 개의 서브 그래프를 도출:
- ACCOUNT → AGREEMENT → DEPOSIT_SUMMARY (파란색)
- LOAN → AGREEMENT → LOAN_SUMMARY (초록색)
이렇게 했을 때의 핵심적인 효과는
- 실제로 가능한 흐름만 보여주기 때문에 더 정확한 Lineage 분석이 가능하다.
- 쿼리 조건을 통해 흐름의 의도를 파악해 의미 기반의 추론이 가능하다.
- 필터 조건을 활용해 단순한 구조보다 더 정밀한 연결성을 분석할 수 있다.
- 그래프 시각화 시, 의미 없는 정보는 흐리게 표현하고 중요한 건 강조할 수 있다.
정리하자면, 단순히 연결돼 있기 때문에 흐름이 있다는 것이 아니라, 필터 조건과 의미가 일치할 때만 흐름이 있다고 보는 것이 Semantic Layer의 핵심이다.
#8. 전체 요약
1. 시스템 개요
- 목적: 데이터 흐름을 시각화하고 분석할 수 있는 계보(lineage) 시스템 설계
- 접근: 메타데이터 기반으로 구조적 + 의미적 분석 수행
2. 메타데이터 저장소 설계
- 다양한 출처(DB, ETL, BI 등)에서 수집한 메타데이터를 저장
- 표준화된 스키마로 정리하여 추후 분석에 활용
3. 시맨틱 메타모델 정의
- DB, 통합, BI 시스템을 포괄하는 일반화된 메타모델(구조) 구성
- 다양한 시스템 간 호환성과 의미 연결성 확보
4. 메타데이터 수집기/스캐너
- 실제 SQL 쿼리, 로그 등에서 메타데이터 자동 수집
- 수동 입력 없이도 시스템이 스스로 구조 파악 가능
5. 쿼리 파싱 및 논리적 경로 분석
- SQL 쿼리 구문을 분석하여 테이블 간 논리적 연결 경로 도출
- SELECT, JOIN, WHERE 등의 조건을 해석하여 흐름 구성
6. 데이터 변환 및 가중치 계산
- 쿼리 내에서 발생하는 변환 식 (예: 계산식, 형 변환 등) 분석
- 변환 복잡도에 따라 노드 간 연결 강도(weight) 계산
7. 그래프 구성 규칙 시스템
- 여러 규칙들을 적용해 신뢰할 수 있는 계보 그래프 생성
- 대표 규칙:
- Rule 1: 동일한 칼럼 명칭은 연결
- Rule 2: 매핑된 칼럼 이름이 달라도, 변환 과정을 고려해 연결
- Rule 3: 직접 연결되지 않았지만 중간 변환을 통해 연결될 수 있는 관계도 탐색
8. Semantic Layer (시맨틱 계층) 계산
- 쿼리 조건 및 필터를 활용해 실제로 흐를 수 있는 데이터 흐름만 시각화
- 관련 없는 노드는 흐리게 처리하고, 관련 있는 노드만 강조
- 의미적 연결성과 조건 중첩을 통해 실제 가능한 흐름만 남김
'Paper review' 카테고리의 다른 글
| [paper review] GloVe: Global Vectors for Word Representation (0) | 2025.03.29 |
|---|---|
| [paper review] Efficient Estimation Of Word Representations In Vector Space (Word2Vec) (1) | 2025.03.27 |

