분산 시스템이 준비되면 시각화를 위해 데이터 마트를 만드는 절차에 들어간다. 그 과정에서 필요한 각종 테이블의 역할과 비정규화 테이블을 만들기까지의 흐름을 살펴보자.
| 팩트 테이블, 시계열 데이터 축적하기
데이터를 구조화하는 과정에서, 팩트 테이블이 압도적으로 많은 부분을 차지한다. 팩트 테이블이 아주 작으면 메모리에 올릴 수 있지만, 그렇지 않으면 열 지향 스토리지에서 데이터를 압축해야 한다. 이렇게 팩트 테이블을 작성하는 방법에는 추가와 치환이 있다.

추가(append)
새로 도착한 데이터만을 증분으로 추가하는 것
치환(replace)
과거의 데이터를 포함하여 테이블 전체를 치환하는 것
그렇다면 언제 추가를 하고, 언제 치환을 해야할까? 효율만을 생각하면 추가가 압도적으로 유리하다. 그러나 추가에는 몇 가지 잠재적인 문제가 있다.
추가의 문제점
- 추가에 실패한 것을 알아채지 못하면 팩트 테이블의 일부에 결손이 발생한다.
- 추가를 잘못해서 여러 번 실행하면 팩트 테이블 일부가 중복된다.
- 나중에 팩트 테이블을 다시 만들고 싶은 경우의 관리가 복잡해진다.
| 테이블 파티셔닝
위와 같은 추가의 문제점을 줄이기 위해 테이블 파티셔닝(table partitioning)이라는 기술을 사용한다. 테이블 파티셔닝이란, 하나의 테이블을 여러 물리적인 파티션으로 나눔으로써 파티션 단위로 정리하여 데이터를 쓰거나 삭제할 수 있도록 한 것이다.

쉽게 말하면, 하나의 테이블을 여러 물리적 조각(파티션)으로 나누는 것이다. 날짜, 시간 단위로 나누면 관리가 쉬워진다.
- 1일 1파티션, 혹은 1시간 1파티션으로 나눠서 데이터 저장
- 만약 잘못된 데이터가 있다면, 그 파티션만 삭제 후 다시 생성!
파티셔닝을 하면 잘못된 데이터만 골라서 수정할 수 있다. 중복을 방지하고, 빠른 삭제와 교체가 가능하다. 운영도 효율적이고 관리도 용이해진다. 대규모 데이터 관리에 유리한 시스템인 것이다.
| 데이터 마트의 치환
데이터 마트의 치환이란, 팩트 테이블 전체를 새로 만드는 방식이다. 기존 데이터를 버리고, 새 데이터로 갈아끼우는 작업이라고 생각할 수 있다.
언제 치환을 쓰는 걸까?
- 데이터가 오래되거나 불필요해져서 삭제가 필요한 경우
- 데이터 처리 시간이 짧고 용량이 저근 경우
- 테이블을 정기적으로 완전히 새롭게 구성하고 싶은 경우
데이터 마트의 경우 데이터양이 한정적이기 때문에, 매번 치환하는 것이 크게 어렵지 않다. 예를 들어, 일일 보고서를 위해 지난 30일 간의 데이터를 매일 꺼내야 한다면? 데이터 마트에서는 치환해서 사용할 수 있다.
치환의 장점은 뭐가 있을까?
- 중간에 데이터가 중복되거나 빠뜨릴 가능성이 거의 없다.
- 스키마 변경 등에 유연하게 대응할 수 있다.
- 오래된 데이터가 자동으로 지워져 데이터 마트가 확대되는 일이 없다.
치환의 단점은 무엇이 있을까?
유일하게 우려되는 것이 있다면, 처리 시간이다. 너무 데이터의 양이 많은 경우 시간이 오래 걸리므로 현실적으로 좋은 선택이 아니다. 이런 경우네는 데이터를 파티셔닝하거나, 기존의 테읻블에 추가해 주의깊게 모니터링 하는 것이 더 나은 선택일 수 있다.
| 집계 테이블로 레코드 수 줄이기
집계 테이블
팩트 테이블을 어느 정도 모아서 집계하면 데이터의 양이 크게 줄어드는데, 이를 집계 테이블(summary table)이라고 한다.
왜 집계 테이블이 필요할까?
- 데이터가 너무 많은 경우, 모든 로그 데이터를 그대로 쓰면 쿼리 성능이 떨어지고 저장 비용도 커진다
- 자주 쓰는 정보만 빠르게 보고 싶은 경우, 주기적으로 확인하는 통계는 미리 계산해두는 것이 효율적이다.
- 집계 테이블에는 중복이 제거되어 있기 때문에 JOIN/WHERE 필터링 시 속도가 개선된다.
일일 집계
일일 집계란 데이터를 1일 단위로 집계한 것

- 일일 집계를 잘 만들면 원래의 데이터가 아무리 대량이어도 데이터 마트가 그다지 커지지 않는다.
Hive를 활용한 일일 집계 예시
-- Hive 예시
CREATE TABLE access_summary STORED AS ORC AS
SELECT
cast(substr(time, 1, 10) AS date) AS dt, -- 날짜
status, -- 상태코드
count(*) AS cnt, -- 해당 날짜/상태별 요청 수
sum(bytes) AS total_bytes -- 해당 날짜/상태별 전송량
FROM access_log_orc
WHERE time BETWEEN '1995-07-10' AND '1995-07-20'
GROUP BY dt, status;
이렇게 하면, 전체 로그가 아니라 날짜와 상태코드를 기준으로 집계된 51개의 레코드만 저장된다. 원본보다 훨씬 가볍지만, 활용도는 높다는 장점이 있다.
카디널리티(cardinality)
카디널리티란, 각 컬럼이 취할 수 있는 값의 종류 수를 말한다.
- 예시(1) : 성별(남/여) > 카디널리티가 낮음
- 예시(2) : IP 주소, 사용자 ID > 카디널리티가 높음
카디널리티가 높을수록 집계 효과가 적고, 레코드 수도 줄어들지 않는다. 따라서 실용적 관점에서는 무조건 집계할 필요가 없다. 최종 레코드 수가 수억 개 수준이라면 집계가 없어도 괜찮다. 최근 MPP 데이터베이스는 비정형 데이터도 빠르게 처리가 가능하므로, 집계 비용과 저장 비용을 효율적으로 고려하는 것이 좋다.
| 스냅샷 테이블로 마스터의 상태를 기록하기
마스터 데이터
업무에서 반복적으로 참조되는 기준 정보를 말한다.
- 고객 정보 (고객 ID, 이름, 생년월일)
- 상품 정보 (상품명, 상품코드, 가격)
- 직워 정보 (사번, 부서, 직책)
- 거래처 정보
마스터 데이터처럼 업데이트 될 가능성이 있는 테이블에 대해서 상태를 기록하는 두 가지 방안이 있다. 그 중 첫 번째가 정기적으로 테이블을 통째로 저장하는 스냅샷 테이블이다.
스냅샷 테이블
마스터 테이블처럼 변경 가능성이 있는 데이터를 보존하기 위한 방법. 일정 주기로 마스터 테이블 전체를 통째로 복사해 저장한다.
- 과거의 상태를 보존해 이후 분석에 활용 가능
- 레코드 수가 많아져도 빅데이터 기술을 활용하면 큰 부담 없음
- 시간이 지날수록 점점 커지기 때문에 팩트 테이블과 유사한 형태
스냅샷 작성 시 유의점
스냅샷을 작성할 때는 날짜(시점)를 언제로 할 것인지 주의해야 한다.
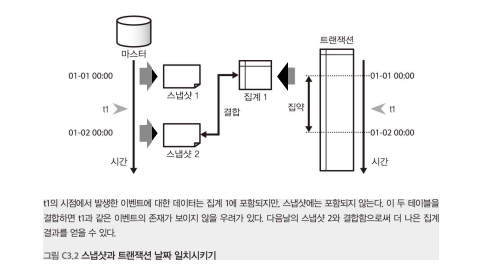
- 1일 0시에 스냅샷을 찍었는데, 실제 이벤트는 전날 23시에 발생했다면 누락될 가능성이 있다.
- 트랜잭션 데이터와 조인할 경우 시간 기준 차이로 인해 분석에 오류가 발생할 수 있다.
- 일반적으로 해당 하루 동안 수집한 데이터로 스냅샷을 구성하는 것이 안전하다. 하루의 시작이 아니라 하루의 끝에 취득하는 것!
스냅샷 테이블을 디멘전처럼 쓰기
스냅샷 테이블을 다른 팩트 테이블과 결합하면 디멘젼 테이블처럼 사용할 수 있다.
WITH users AS (
SELECT * FROM users_snapshot WHERE date = '2017-01-01'
)
SELECT ...
FROM fact_table f
JOIN users u ON u.id = f.user_id
위의 쿼리처럼 스냅샷의 날짜를 지정해 과거의 마스터 테이블을 볼 수 있다.
SELECT ...
FROM fact_table f
JOIN users_snapshot u
ON u.id = f.user_id AND u.date = f.date
팩트 테이블과 스냅샷 테이블을 날짜를 포함해서 결합할 수 있다. 팩트 테이블이 날짜 정보를 포함하고 있다면 날짜 조건으로 직접 조인하는 것이다.
팩트 테이블(매출, 클릭 기록 등)은 특정 시점의 기록이다. 이걸 분석하기 위해서는 그 시점의 마스터 데이터도 필요하다.
실제 마스터 테이블에는 최신 상태만 남아있기 때문에, 스냅샷 테이블을 만들어 보관해두어야 한다. 삭제되지 않도록 데이터 레이크나 데이터 웨어하우스와 같은 영구적이 저장소에 보관해야 한다.
또한, 미리 테이블을 결합해 비정규화한 상태에서 스냅샷 해도 상관없다. 데이터를 분석할 때는 결국 모든 테이블을 결합해야 하기 때문에 처음부터 비정규화한 상태로 스냅샷 하는 것이 더 편하다.
| 이력 테이블
마스터 데이터의 상태를 기록하는 또 다른 방법으로는 이력 테이블(History Table)이 있다. 마스터 데이터를 매번 스냅샷으로 전부 저장하면 비효율적이므로, 변경이 생길 때만 기록하는 방식이다.
이력 테이블
마스터 데이터가 바뀌었을 때의 기록만 따로 남기는 방법으로, 저장 공간 절약이 가능하다.
- 나중에 과거의 마스터 상태를 복원하려면 복잡한 쿼리가 필요하다
- 완전한 상태의 마스터를 즉시 얻기 어려워 디멘전 테이블로 쓰기 어렵다.
-- 최근 1년간 변경 기록 중 가장 최신 레코드만 추출
SELECT * FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY date DESC) number
FROM users_history
WHERE date >= current_date() - INTERVAL '365' DAYS
) t
WHERE number = 1
이 쿼리는 최근 1년 간의 변경 이력을 추적해 가장 최신 상태의 마스터 정보를 복원하는 쿼리이다.
이력 테이블은 저장 공간 절약에는 좋지만, 복원/분석이 어렵기 때문에 매일 스냅샷을 찍는 것이 더 나을 수도 있다. 마스터 테이블을 디멘전으로 쓰고 싶다면, 정기 스냅샷 방식이 더 안전하고 간편하다.
| 디멘젼 추가로 비정규화 테이블 완성하기
팩트 테이블에 디멘젼 테이블을 결합하면 분석 목적에 맞춘 비정규화 테이블을 만들 수 있다.
- 이때 디멘젼 테이블은 스냅샷일 수도 있고, 별도로 만든 중간 테이블일 수도 있다.
웹사이트 액세스를 분석해야 한다고 생각해보자.
CREATE TABLE sessions AS
SELECT session_id,
min(time) AS min_time, -- 처음 액세스 시간
max(time) AS max_time -- 마지막 액세스 시간
FROM access_log
GROUP BY session_id;
이 쿼리를 통해 session_id별 처음 액세스 시간, 마지막 액세스 시간을 파악하는 디멘전 테이블을 생성할 수 있다.
디멘전 컬럼은 꼭 필요한 것만 써야한다.
- 카디널리티가 높은 컬럼은 조인하더라도 테이블 크기가 줄어들지 않아 오히려 성능이 저하될 수 있다.
- 꼭 필요한 디멘전만 남기고, 시각화/분석에 불필요한 디멘전은 제거하는 것이 효율적이다
집계 수행
디멘전 테이블과 팩트 테이블을 조인한 뒤에는 분석 목적에 맞는 지표를 집계해야 한다.
세션 단위로 이용자 경로를 분석하고 싶은 경우가 있다고 생각해보자.
SELECT
date_trunc('day', a.time) AS date,
date_diff('day', b.min_time, a.time) AS days_after_session_start,
count(*) AS visit_count
FROM access_log a
JOIN sessions b ON b.session_id = a.session_id
GROUP BY 1, 2;
위 쿼리는 각 날짜를 기준으로, 세션 시작 후 며칠 뒤에 접속이 얼마나 발생했는지를 분석하려는 쿼리이다.
CSV로 내보내거나 마트로 저장하기
이렇게 만든 비정규화 테이블은 분석과 시각화를 위한 최종 테이블이므로, CSV로 내보내거나 데이터 마트에 적재하면 된다.
팩트 테이블에 꼭 필요한 디멘전만 조인해서 불필요한 카디널리티를 줄이고, 그 결과를 집계(group by)한 후 CSV나 마트에 저장하면 최종 분석용 테이블을 만들 수 있다.
'Database' 카테고리의 다른 글
| [Database] 벌크형 vs 스트리밍형 : 데이터를 움직이는 두 가지 방식 (6) | 2025.08.03 |
|---|---|
| [Database] 나에게 맞는 데이터 분석 프레임워크 선택하기 (feat. Hive, Presto, Spark) (2) | 2025.07.30 |
| [Database] 분산 처리 프레임워크 (4) 대화형 쿼리 엔진 Presto의 구조 (3) | 2025.07.30 |
| [Database] 분산 처리 프레임워크 (3) 구조화부터 비정규화까지: Hive로 완성하는 데이터 마트 구축 A to Z (1) | 2025.07.29 |
| [Database] 분산처리 프레임워크 (2) Hadoop이란? 개념부터 동작 원리까지 (1) | 2025.07.28 |



