본 게시글은 '빅데이터를 지탱하는 기술' 교재 CHAPTER1 빅데이터의 기초 지식 부분을 정리한 내용입니다. 이미지 출처는 모두 '빅데이터를 지탱하는 기술' 입니다.
| Hadoop과 NoSQL

웹 서버 등에서 생성된 데이터는 RDB와 NoSQL 등의 텍스트 데이터에 저장된다. 그 후 모든 데이터가 Hadoop으로 모이고, 거기서 대규모 데이터 처리가 실행된다.
Hadoop
대용량의 데이터를 나눠서 저장하고 처리하는 시스템. 쉽게 말해, 아주 큰 데이터를 (빅데이터) 여러 컴퓨터에 나눠서 처리하는 방법이다.
- 수천 대 단위의 컴퓨터를 이용해 스토리지와 데이터를 순차적으로 처리할 수 있는 구조를 관리하는 프레임워크\
Hadoop의 구성
| HDFS (Hadoop Distributed File system) | 데이터를 여러 컴퓨터에 쪼개서 분산 저장하는 파일 시스템 분산 저장소 + 분산 처리 시스템 (MapReduce) |
| MapReduce | 데이터를 나눠서 동시에 계산하고, 결과를 합치는 방식 |
HDFS가 저장을 담당하는 플랫폼이라면, MapReduce는 그 안에서 데이터를 처리하는 엔진을 말한다. MapReduce는 저장된 데이터를 나눠서(Map) 동시에 여러 서버가 계산하고, 결과를 합쳐서(Reduce) 하나로 만드는 프로그램 방식이다.
NoSQL 데이터 베이스
관계형이 아닌 데이터베이스를 통칭하는데, 빈번한 읽기/쓰기 및 분산처리에 강점을 가지는 데이터베이스다. 쉽게 말해, 엑셀처럼 테이블 형태로 정리하지 않아도 되는, 유연한 데이터베이스이다.
- 모여진 데이터를 나중에 집계하는 것이 목적인 Hadoop과 다르게 NoSQL은 애플리케이션에서 온라인으로 접속
- RDB에 비해 읽기, 쓰기가 빠르고 분산 처리에 뛰어나다.
NoSQL 유형
| Key-Value store | 딕셔너리처럼 key에 value 저장 | Redis, DynamoDB |
| document store | JSON 같은 문서 형태로 저장 | MongoDB |
| wide-column sotre | 열 단위로 저장, 분석에 유리 | Cassandra, HBase |
| 그래프형 | 관계 중심 데이터 저장 | Neo4j, TigerGraph |
| 데이터 웨어하우스
데이터 웨어하우스 (Data Warehouse)
여러 시스템에서 모은 데이터를 한 곳에 모아 분석에 용이하게 정리해놓은 데이터 저장소
- 각 부서에서 발생한 데이터들을 한 데 모아두고, 그것을 보고서처럼 정리해 의사결정에 쓸 수 있게 만든 시스템이다.
기술이 발전하면서 기존 데이터웨어하우스만으로는 감당하기 어려운 수준으로 데이터가 많아지자 분산 처리 시스템이 도입되었다.
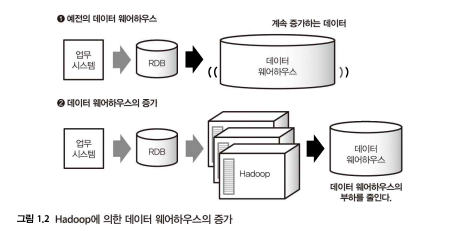
| 전통적 데이터 웨어하우스 | Hadoop | |
| 처리 방식 | 데이터 저장 후 분석 | 데이터를 분산 저장 + 병렬 분석 |
| 분석 범위 | 주로 정형 데이터 | 웹 로그, 센서 데이터 같은 비정형 데이터까지 가능 |
| 유연성 | 고정된 스키마 필요 | 유연하게 다양한 데이터 수용 가능 |
| 비용 | 고가 (상용 솔루션) | 오픈소스 기반으로 저렴하게 구축 가능 |
가속도적으로 늘어나는 데이터 처리에 Hadoop을 도입하고, 비교적 작은 데이터 혹은 중요한 데이터만을 데이터 웨어하우스에 넣는 하이브리드 방식이 늘어나게 되었다. 이를 통해 데이터 웨어하우스의 부하를 줄일 수 있게 되었다.
| 클라우드 서비스와 데이터 디스커버리
클라우드 서비스
인터넷을 통해 컴퓨터 자원(저장공간, 서버, 소프트웨어 등)을 빌려쓰는 서비스를 말한다. 쉽게 말해, 내 컴퓨터에 설치하지 않아도, 인터넷만 있으면 다른 컴퓨터(클라우드)에서 모든 것을 처리해주는 것!
- 분산 처리를 위한 하드웨어를 준비하고 관리하기 어려워 클라우드 시스템을 활용
클라우드 서비스의 유형
| IaaS(Infrastructure as a Service) | 서버·스토리지 같은 기반 시설을 빌려줌 | AWS EC2, Azure VM |
| PaaS(Platform as a Service) | 개발할 수 있는 환경/플랫폼을 빌려줌 | Google App Engine |
| SaaS(Software as a Service) | 소프트웨어를 인터넷으로 제공 | Gmail, Zoom, Notion |
데이터 디스커버리(data discovery)
대화형으로 데이터를 시각화하여 가치 있는 정보를 찾으려고 하는 프로세스로, 셀프서비스용 BI(business intelligence tool) 도구로 불린다.
| 데이터 파이프라인
데이터 파이프라인
차례대로 전달해나가는 데이터로 구성된 시스템을 데이터 파이프라인(data pipeline)이라고 한다. 구체적으로 데이터를 수집해서 가공하고 저장하거나 분석하는 일련의 과정이다.
데이터를 목적지까지 자동으로 옮기고 정리해주는 라인!
데이터 파이프라인의 구성 요소
| 구성 | 역할 | 도구 |
| 추출 (Extract) | 데이터를 가져오기 | Kafka, API, DB |
| 변환 (Transform) | 데이터를 가공/정제하기 | Python, Spark, SQL |
| 적재 (Load) | 저장소에 넣기 | AWS S3, BigQuery, Redshift |
ETL 파이프라인과 ELT 파이프라인
데이터를 처리하는 순서에 따라 ETL 파이프라인과 ELT 파이프라인으로 구분된다.

| 순서 | 추출 → 변환 → 저장 (ETL) | 추출 → 저장 → 변환 (ELT) |
| 처리 위치 | 중간 서버나 외부 처리도구에서 데이터 가공 | 저장소 내부(DB, DWH 등)에서 가공 |
| 적합한 환경 | 데이터가 작고 정제돼야 할 때→ 전통적인 DWH 환경 | 데이터가 엄청 크고 유연해야 할 때→ 클라우드 기반 환경 |
| 사용 기술 | Python, Spark, ETL 전용 툴(Airflow, Talend 등) | BigQuery, Snowflake, Redshift 등 (SQL 기반 변환) |
| 장점 | 정제된 상태로 저장되므로 품질 관리 용이 | 빠르게 적재하고, 나중에 가공하니 속도 빠르고 유연 |
| 단점 | 변환 과정이 느릴 수 있음 | 저장소가 처리 부담을 더 짐 |
데이터의 수집 (그림 1,2)
데이터 파이프라인은 데이터를 수집하는 데서 시작한다. 각각 다른 원천에서 데이터를 전송(transfer)하는데, 그 방법에는 벌크형과 스트리밍형 크게 두 가지가 있다.
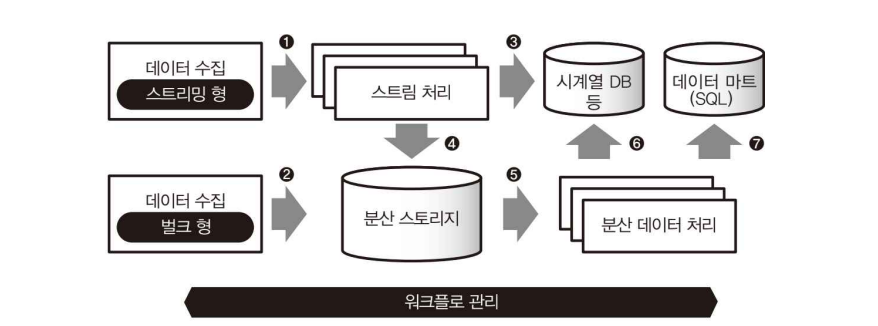
| 벌크형 | 이미 저장된 데이터를 한 번에 모아서 가져오는 방식 |
| 스트리밍형 | 데이터가 생기는 즉시 실시간으로 보내는 방식 |
기존의 데이터 웨어하우스 같은 시스템에서는 이미 쌓인 데이터를 정기적으로 한꺼번에 처리하는 벌크방식을 주로 채택했다. 하지만 요즘에는 모바일 앱, 웹, IoT 기기처럼 데이터가 계속해서 실시간으로 쏟아지기 때문에 스트림 처리가 더 중요해졌다.
스트림 처리
스트림 처리란, 스트리밍형으로 받은 데이터를 실시간으로 처리하는 것을 말한다.
[예시 상황] 30분마다 들어오는 데이터를 바로 그래프화 해서 보고 싶은 경우, 스트림 처리가 필요함
- 이때 시계열 데이터베이스(그림 3)를 통해 실시간으로 어떤 일이 일어나고 있는지 확인이 가능함
- 스트림 처리는 실시간 분석은 빠르지만, 오랜 기간 축적된 데이터를 분석하기에는 효율적이지 않음
배치 처리 (그림 4,5)
배치 처리는 정해진 시간마다 한꺼번에 처리하는 방식을 이야기함. 매출 통계, 월간 리포트 등이 그 예시이며 대용량 데이터를 효율적으로 처리할 수 있음
스트림 처리는 실시간 반응을 살피는데 적절하고, 배치 처리(벌크형)는 많은 데이터를 모아서 분석할 때 유리하다!
| 분산 스토리지와 객체 스토리지
분산 스토리지 (그림 2,4)
수집된 데이터는 분산 스토리지에 저장된다. 여기서 분산 스토리지란, 데이터를 여러 컴퓨터에 나눠서 저장하는 시스템을 말한다.
- 하나의 컴퓨터에 저장하지 않고 여러 대의 컴퓨터(서버)나 디스크에 쪼개서 저장
- 데이터를 많이 저장하거나 동시에 빠르게 처리할 수 있다.
객체 스토리지
파일 하나하나에 이름(키)를 붙여서 저장하는 방식으로, 대표적인 예시는 Amazon S3(클라우드에서 자주 사용하는 저장소)가 있다.
- 데이터를 폴더처럼 저장하지 않고, 각 파일을 객체처럼 다뤄서 이름으로 구분해 저장함
NoSQL 데이터베이스와 분산 스토리지
NoSQL 데이터베이스(비정형 데이터 저장용)도 여러 컴퓨터에 데이터를 나눠서 저장할 수 있다.
- 앱, 웹처럼 많은 데이터를 읽고 쓸 때 NoSQL이 빠르고 효율적이다.
- 확장성도 중요하기 때문에, 나중에 데이터를 얼마나 늘릴 수 있는지 고려해서 선택해야 한다.
| 워크플로 관리 (workflow management)
워크플로우 관리
전체 데이터 파이프라인의 동작을 관리하기 위해서 워크플로우 관리 기숟을 사용한다.
- 매일 정해진 시간에 배치 처리를 스케줄대로 실행
- 오류 발생 시 관리자에 통지 등
'Database' 카테고리의 다른 글
| [Database] 빅데이터의 탐색 (2) 열 지향 스토리지 (3) | 2025.07.22 |
|---|---|
| [Database] 빅데이터의 탐색 (1) 크로스 집계 (0) | 2025.07.22 |
| [Database] 빅데이터 기초 지식 (2) 데이터 웨어하우스와 데이터 마트 (0) | 2025.07.22 |
| [Database] 관계형 데이터 모델 (2) | 2025.07.21 |
| [Database] 데이터베이스의 개념 (0) | 2025.07.21 |



